Índice de contenido
Si eres seguidor de las artes marciales mixtas, o MMA, seguramente estés al tanto que el famoso Ilia Topuria ha hecho historia esta semana tras vencer en apenas dos minutos a su rival para convertirse así en doble campeón mundial.
Bueno, si no eres seguidor del tema probablemente también te hayas enterado, porque a mi no podría importarme menos y ya me ves. En todo caso, le dio un golpe a su contrincante que lo tumbó nada más empezar.
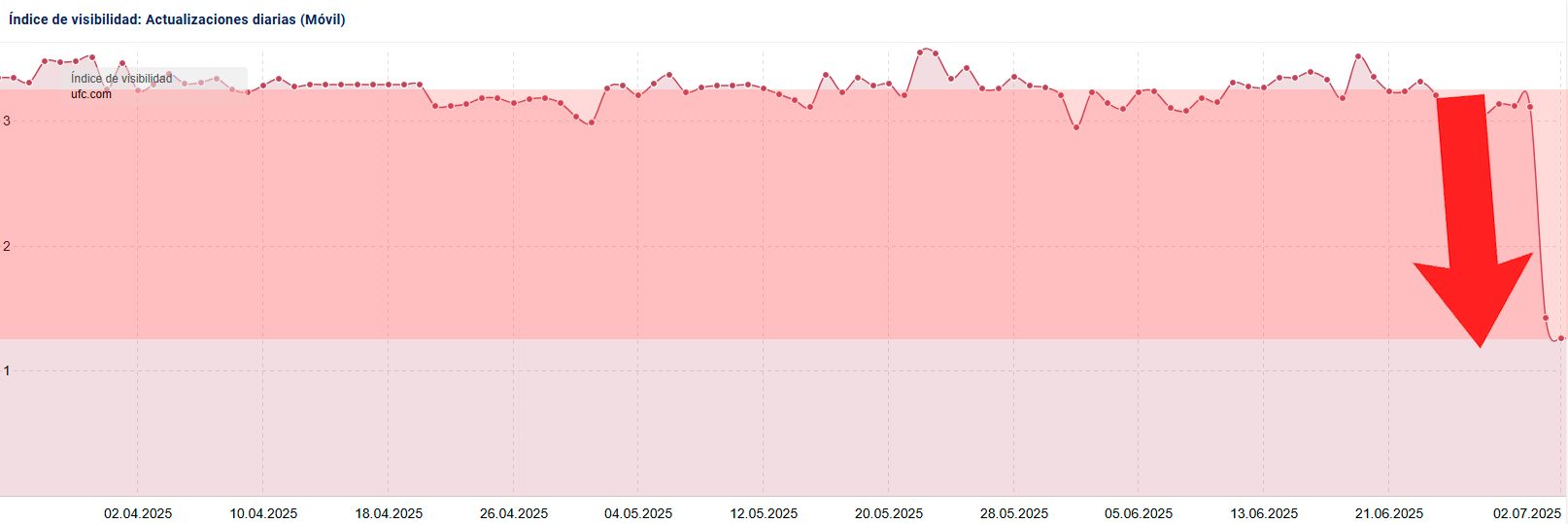
Bien, pues Google ha hecho lo propio con la web oficial de la organización de estos combates, la UFC. Solo que en lugar de en 2 minutos, en 2 días. En tan poco tiempo ha perdido ya cerca del 75% de visibilidad online según Sistrix.
Paracaidismo digital.
¿Qué ha pasado aqui? No lo sabemos. ‘Eso es el Core Update de Google que le ha pegado’, puede que estés pensando. Y no sería mala opción ya que se ha lanzado efectivamente hace dos días y coincide en tiempos perfectamente.
Pero no es eso.
Como siempre, vamos a ir viendo todo hasta dar con la tecla. Es hora de un nuevo #CSIGoogle.
Lo primero es lo primero ¿Qué está cayendo?
En toda escena del crimen, lo primero que hemos de saber es quién es la víctima. En nuestro caso, las victimas son las búsquedas por las que la web está empeorando su posicionamiento o directamente desapareciendo.
Veamos una comparativa de las búsquedas y sus posiciones antes y después de la debacle. Atención porque en 2 días ha empeorado o desaparecido para 1.438 búsquedas. Torta gorda.
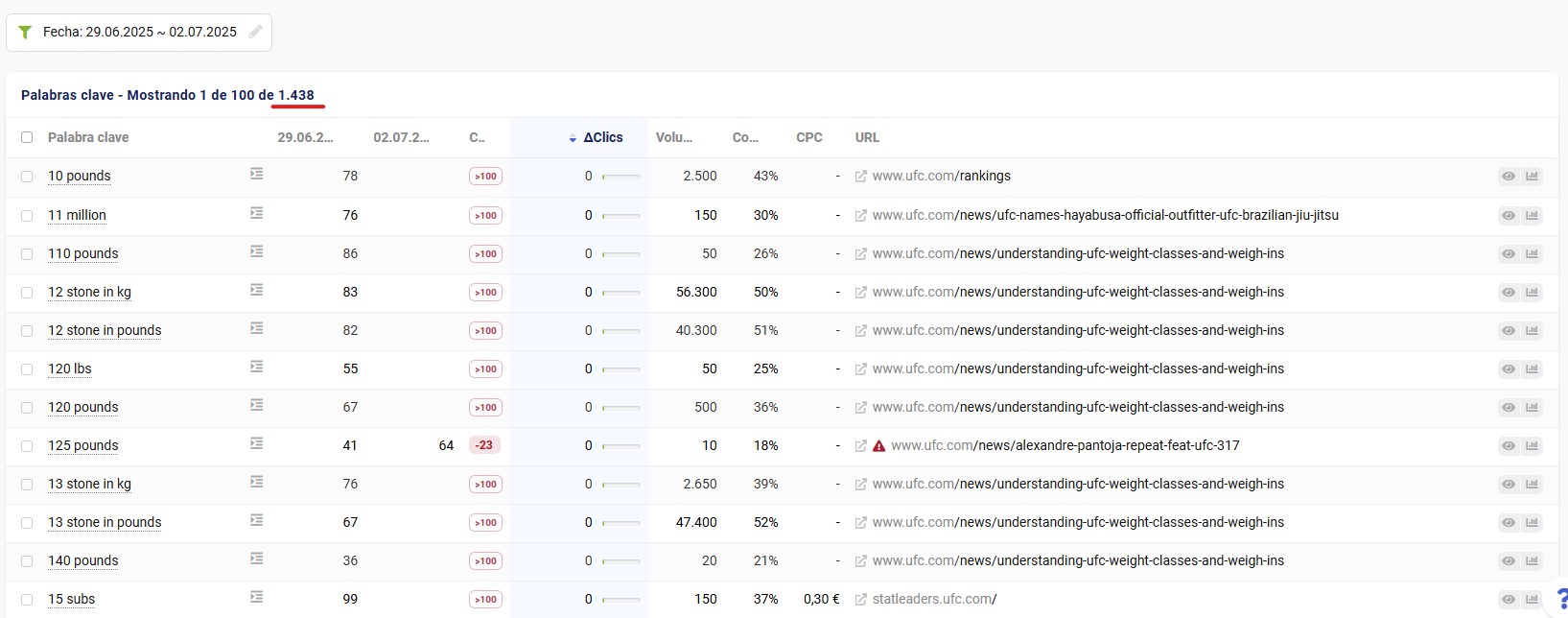
Pero es que aún hay más. Si filtramos solo por las desaparecidas (es decir, no salir ni en el TOP100)… quedan 1.139. Es decir, el 80% de búsquedas es que se evaporan.
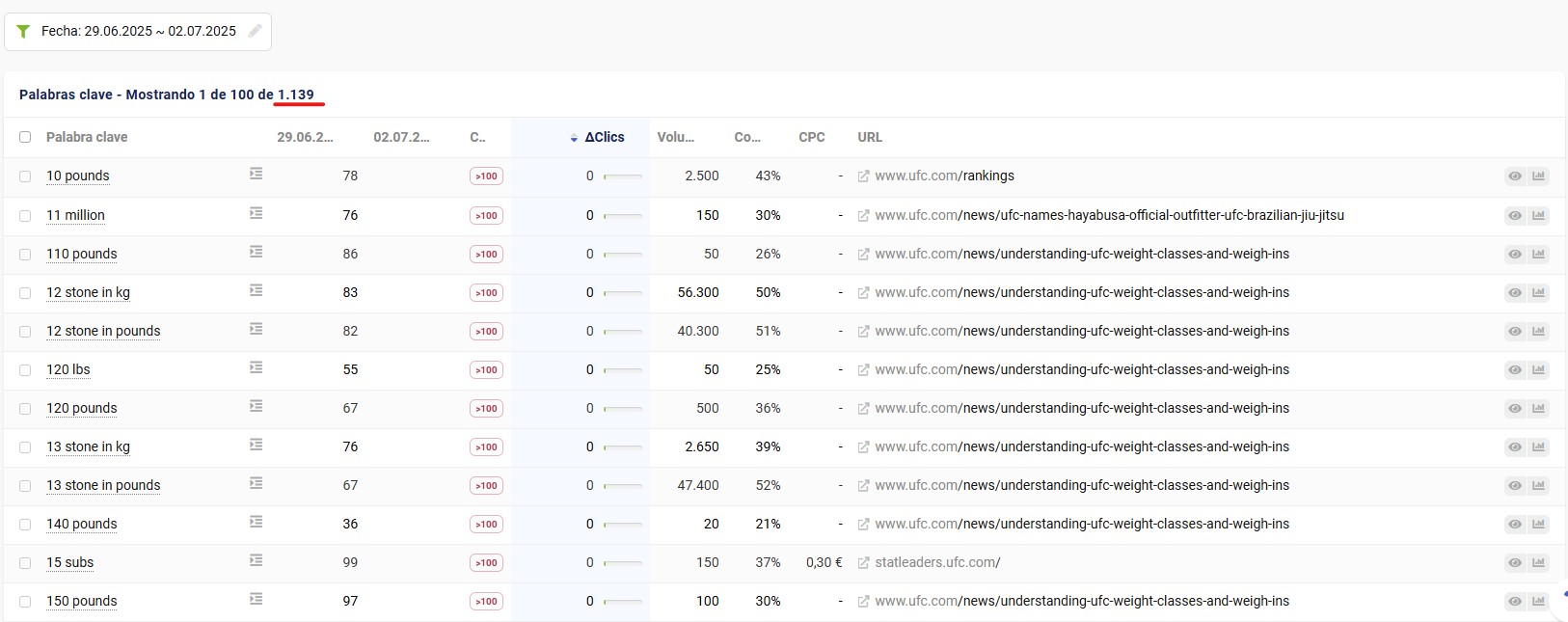
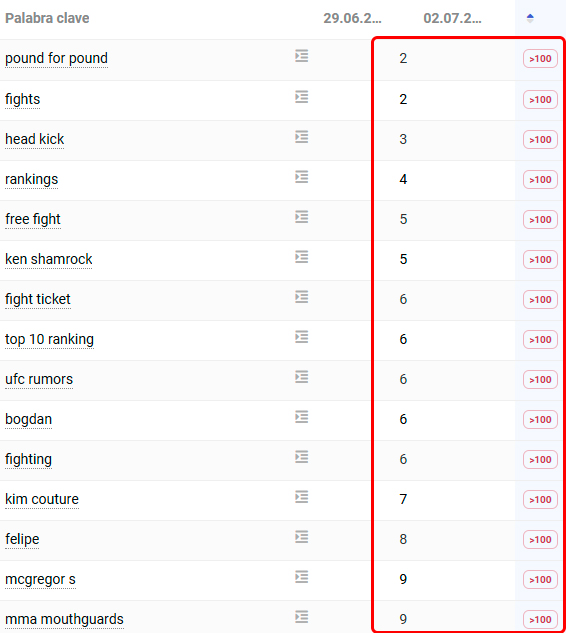
Muchas estaban posicionando en TOP1 o similar ¿eh? Y se van del TOP100. Esto es muy definitorio porque nos habla muy a las claras que estamos ante un problema técnico. Y uno gordo.
Cuando una web es afectada por un cambio algorítmico pierde más o menos posiciones, pero no desaparece de 1ª posición como si nunca hubiera existido. Y menos en una web con el renombre de la UFC. Ahí pasa algo.
From Hero to Zero.
Bien, una vez sabemos qué ha caído, vamos a ver en qué páginas. Igual por ahí podemos sacar algo en claro: que la caída se concentre en unas pocas URL’s, o en una sola tipología como las fichas de jugadores o los artículos del blog… cualquier patrón que nos ayude a seguir tirando del hilo.
Exporto todo a un Google Sheets, listo las URL’s, cuento las palabras clave que tenía asociada cada una de ellas… en un par de fórmulas sencillas lo tenemos. Pero parece algo bastante generalizado, más de 400 páginas caen en mayor o menor medida y cada una de su padre y de su madre.
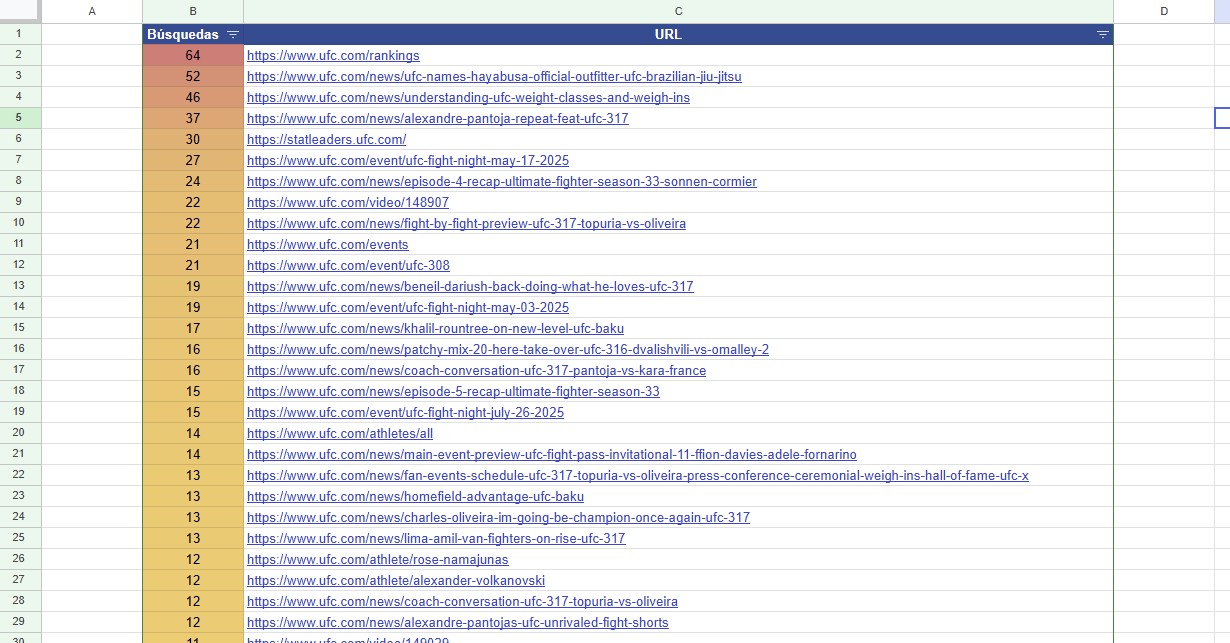
Lo que sea que pase, es a nivel sitio web. Nada de secciones ni páginas concretas. Seguimos.
El motivo de la caída
Al poco de empezar a chafardear una a una las diferentes páginas de ese Google Sheets en el mismo buscador salta la sorpresa.
No están indexadas. Complicado así aparecer en ningún resultado de búsqueda, claro.
Fíjate por ejemplo en ésta:
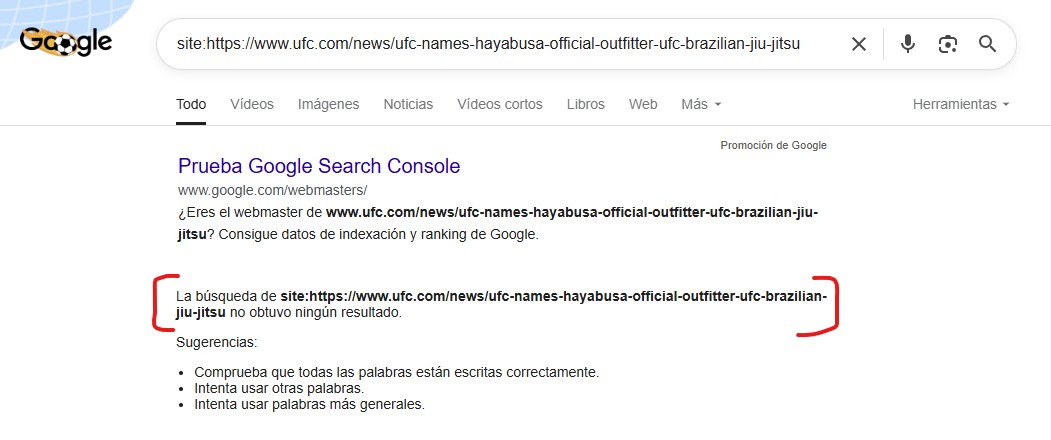
O en esta otra, que aunque devuelva un resultado no es la misma que estoy poniendo yo:
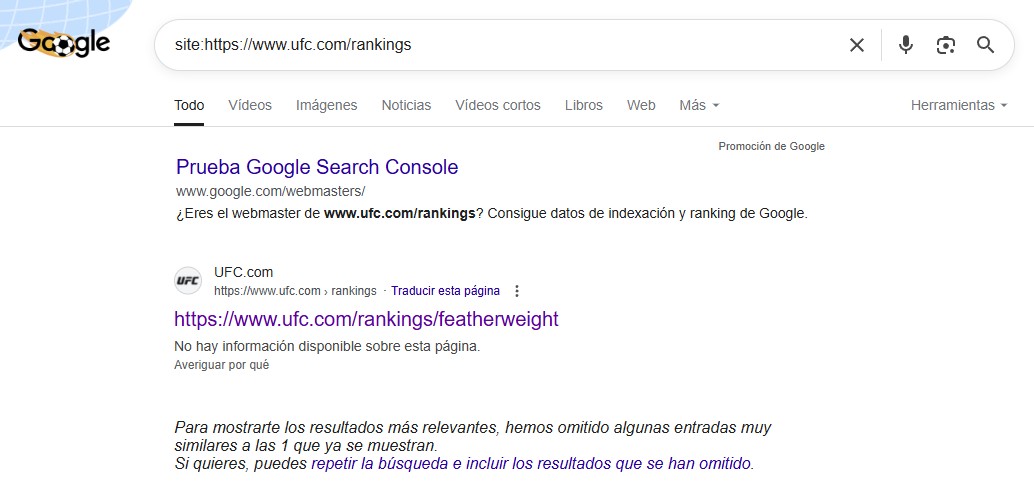 Bueno, pues así podría ir poniendo el pantallazo de todas ellas, pero dejo solo una más y ya se entiende a lo que voy:
Bueno, pues así podría ir poniendo el pantallazo de todas ellas, pero dejo solo una más y ya se entiende a lo que voy:
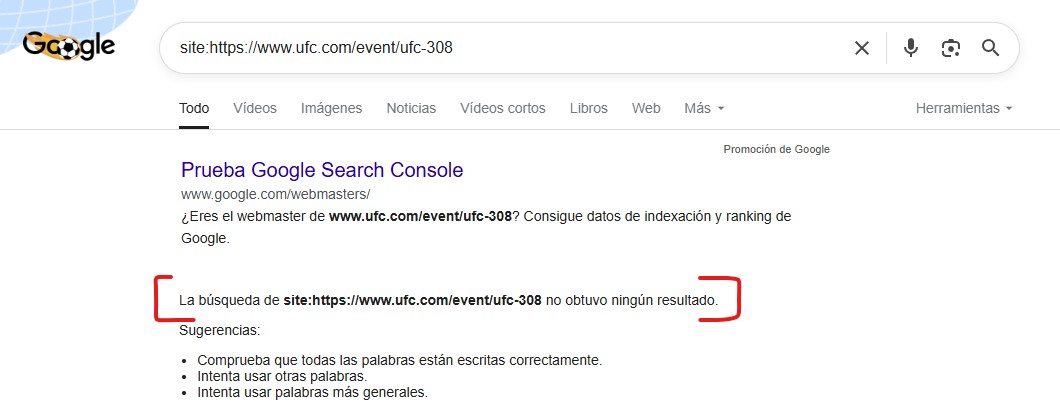
Aquí al menos ya tenemos el porqué de la caída de visibilidad. El sitio web se está desindexando a velocidad récord, desapareciendo de Google todas sus páginas que antes estaban posicionadas… y muy bien posicionadas ¿Qué narices ha pasado aquí?
Nos falta saber la causa de dicha desindexación. Huele a temita técnico de los que me gustan.
Profundizando en la investigación: En busca del fallo técnico
A ver, pensemos. Cosas. Aspectos técnicos que podrían hacer que una web en su conjunto caiga a pique.
Rastreo
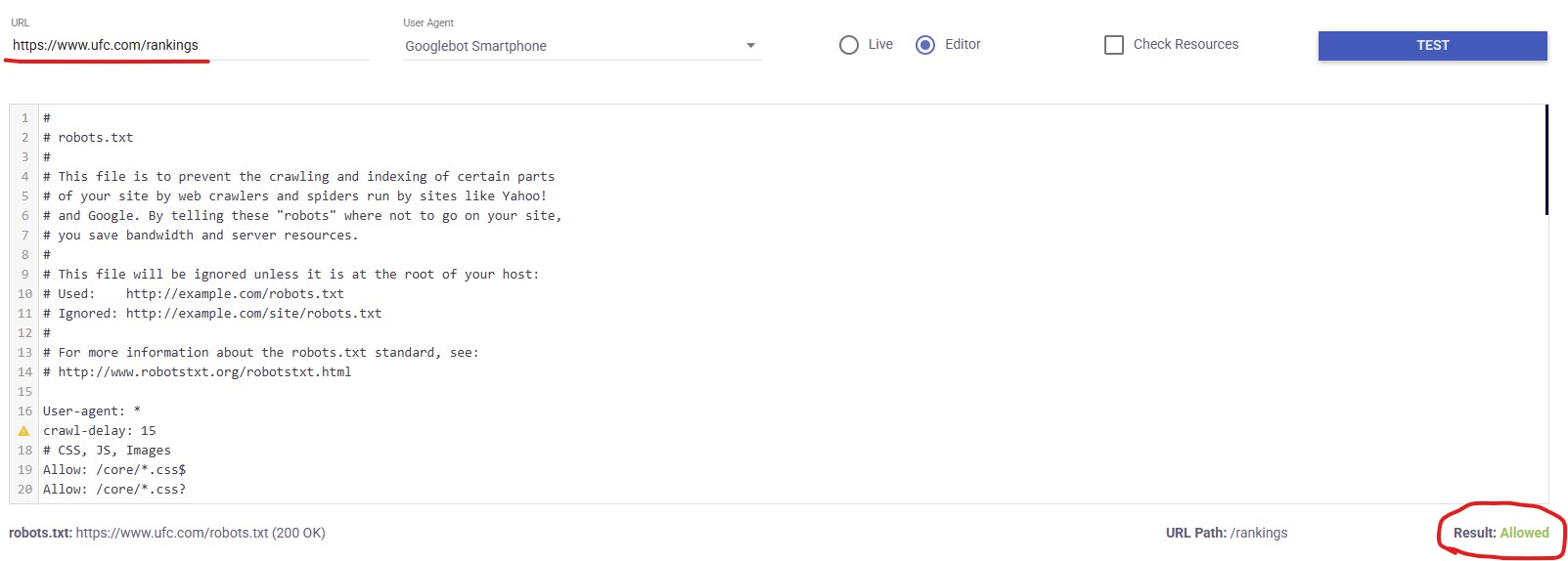
Bien, podemos empezar viendo si Google es capaz de rastrear las diferentes páginas. Miremos el archivo robots.txt, ya que para algo es la herramienta que tenemos como SEO para definir ese tipo de cosas.
A veces pasa por ejemplo que desde IT se hace algún cambio en la web en la versión en desarrollo, se vuelca a la versión en producción y se olvidan el ‘detalle’ de quitar la prohibición de rastreo con un ‘Disallow: /’
Por suerte, no es el caso. Su robots.txt tiene directivas de permisos y prohibiciones, pero nada que haga saltar las alarmas. Se ve un archivo trabajado y bien gestionado.
Podemos incluso confirmarlo pasando una de las páginas más afectadas por la caída en este testeador maravilloso y ver que efectivamente el rastreo por parte del bot mobile de Google está permitido.
Indexación
Ok, sabemos que puede rastrear las páginas, sigamos ahora analizando si las páginas son indexables en su base de datos. Veamos.
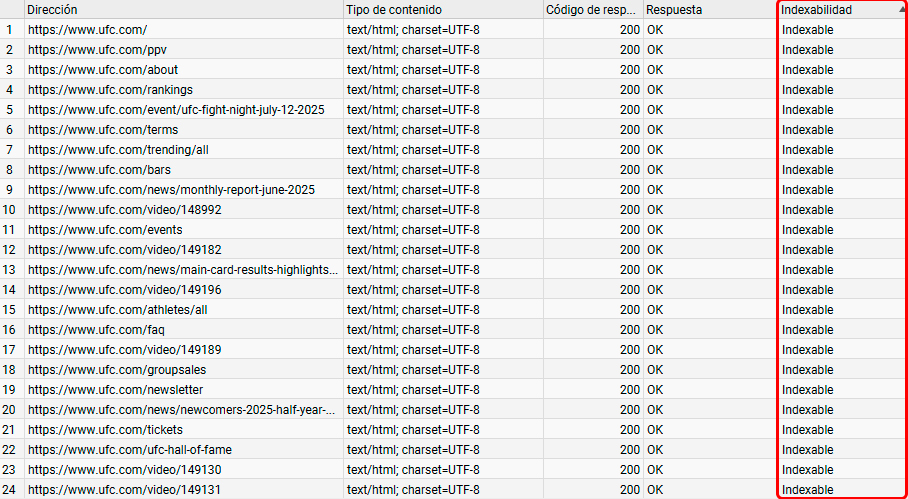
Nada, todo correcto por aquí también. He puesto un pantallazo de Screaming Frog para que veas que en general toda la web es perfectamente indexable, al menos las páginas que deberían serlo, pero es que si vamos a detalle a por ejemplo la que más palabras clave ha perdido nuevamente… cuenta con una indexabilidad envidiable.
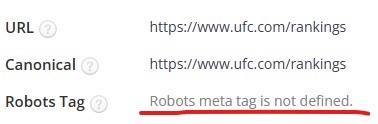 Recuerda que en lo que respecta a la meta etiqueta ‘Robots’:
Recuerda que en lo que respecta a la meta etiqueta ‘Robots’:
- INDEX = Indexable
- NOINDEX = No indexable
- NO PONER NADA = Indexable
Así que aquí no hay nada que rascar. Sigamos buscando.
Renderizado
Vale, pues vamos a la vieja confiable. Con diferencia uno de los principales ‘asesinos’ de muchos #CSIGoogle… el RENDERIZADO.
 Google puede rastrear las URL’s pero ¿ve correctamente el contenido o no? Vamos a verlo.
Google puede rastrear las URL’s pero ¿ve correctamente el contenido o no? Vamos a verlo.
Para ello voy a tirar de otra herramienta online que suele funcionar muy bien casi siempre para simular como ve el buscador una página, la herramienta en cuestión es Fetch & Render y la puedes encontrar aquí.
¡Uy! Ahora que me acuerdo, déjame hacer un poco de enlazado interno y recomendarte este post que hice sobre 6 formas de ver tu web como si fueras Google.
Bueno perdón, lo que te decía. Ponemos ahí una URL de ejemplo y… SE VE BIEN.
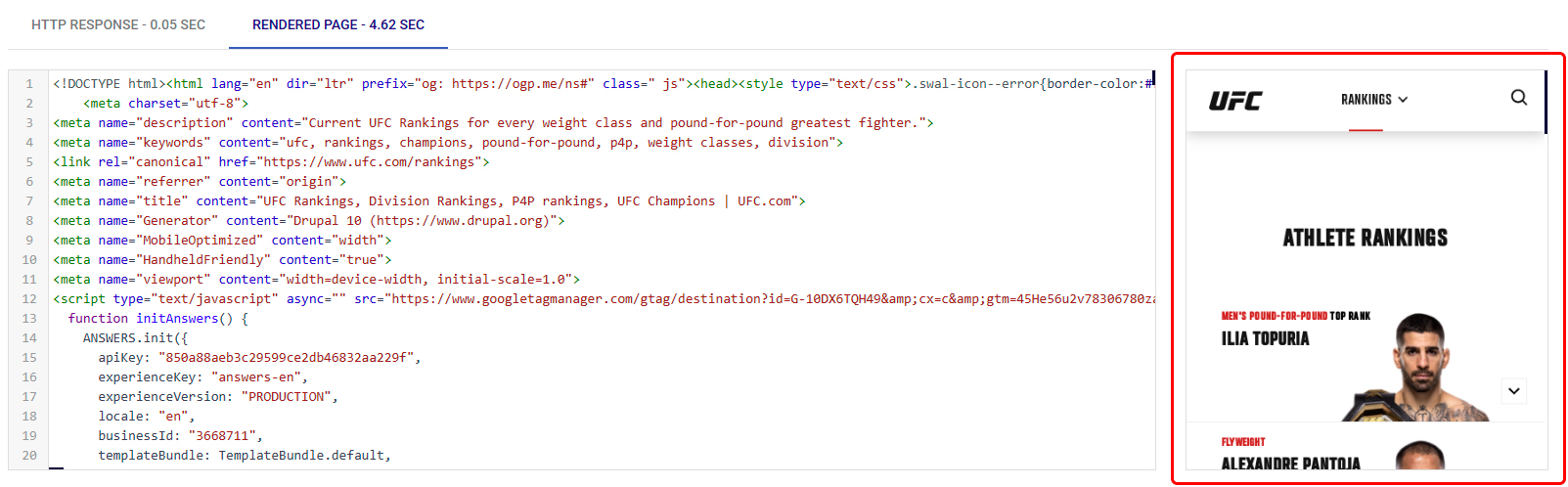
¡¿Pero será posible?! ¡¿Es que no me va a dejar encontrar el puñetero problema para irme tranquilo a dar una vuelta con las horas que son?!
Y ENTONCES, recuerdo una cosa.
Y es que esta herramienta como he dicho va muy bien CASI siempre. Pero una vez me jugó una mala pasada. Y yo creí que Google veía una cosa que en realidad no veía por confiar ciegamente en ella. Y desde entonces… yo hago doble comprobación.
¿Cuál es la forma de salir de dudas? Viendo que nos dice el propio Google. Vamos a Search Console, ponemos en el buscador de arriba la página que queramos y le damos después a ‘Probar URL publicada’ y tras unos segundos nos enseñara un pantallazo con lo que ve.
¿El problema? Que si no tienes una web dada de alta en tu Search Console, pues no vas a poder analizar ahí sus URL’s. Y yo no tengo acceso a la propiedad del sitio de la UFC.
¿La solución? Ser un poco zorro.
Coges cualquier URL de una de tus webs (como si te la inventas) y haces una redirección hacia la página que quieras probar de la web que sea. En mi caso por ejemplo he redirigido https://carlosortega.page/test/ a https://www.ufc.com/events para hacer el test y salir de dudas.
Le damos y… VAYA VAYA VAYA.
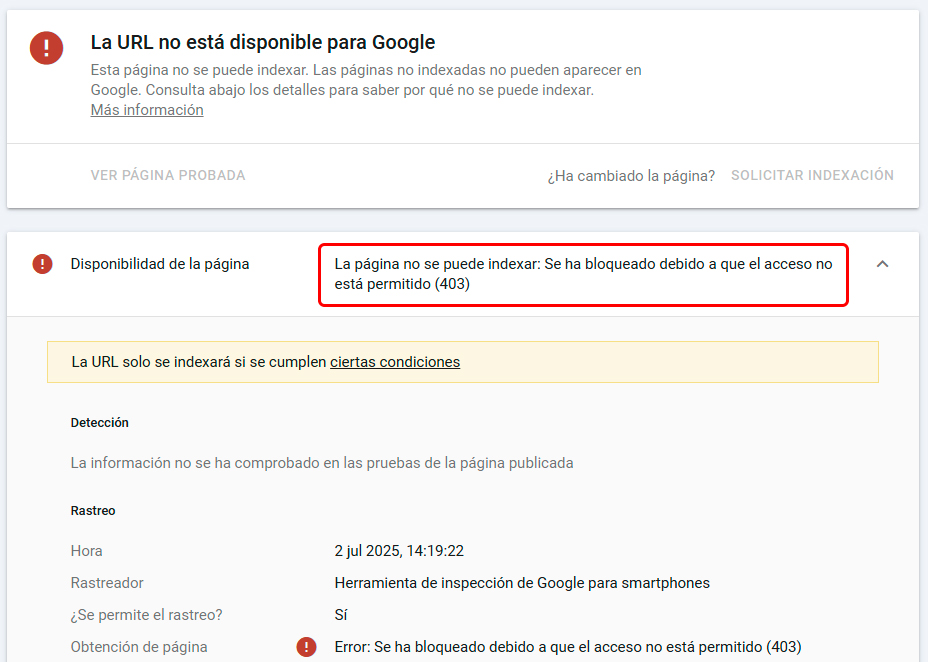
Ese mensaje no es normal, no es un problema del truquito del redireccionamiento. Mira por ejemplo en este otro caso donde hice exactamente lo mismo, con la misma URL de /test pero a la web de Homer Simpson. Se ve perfectamente:
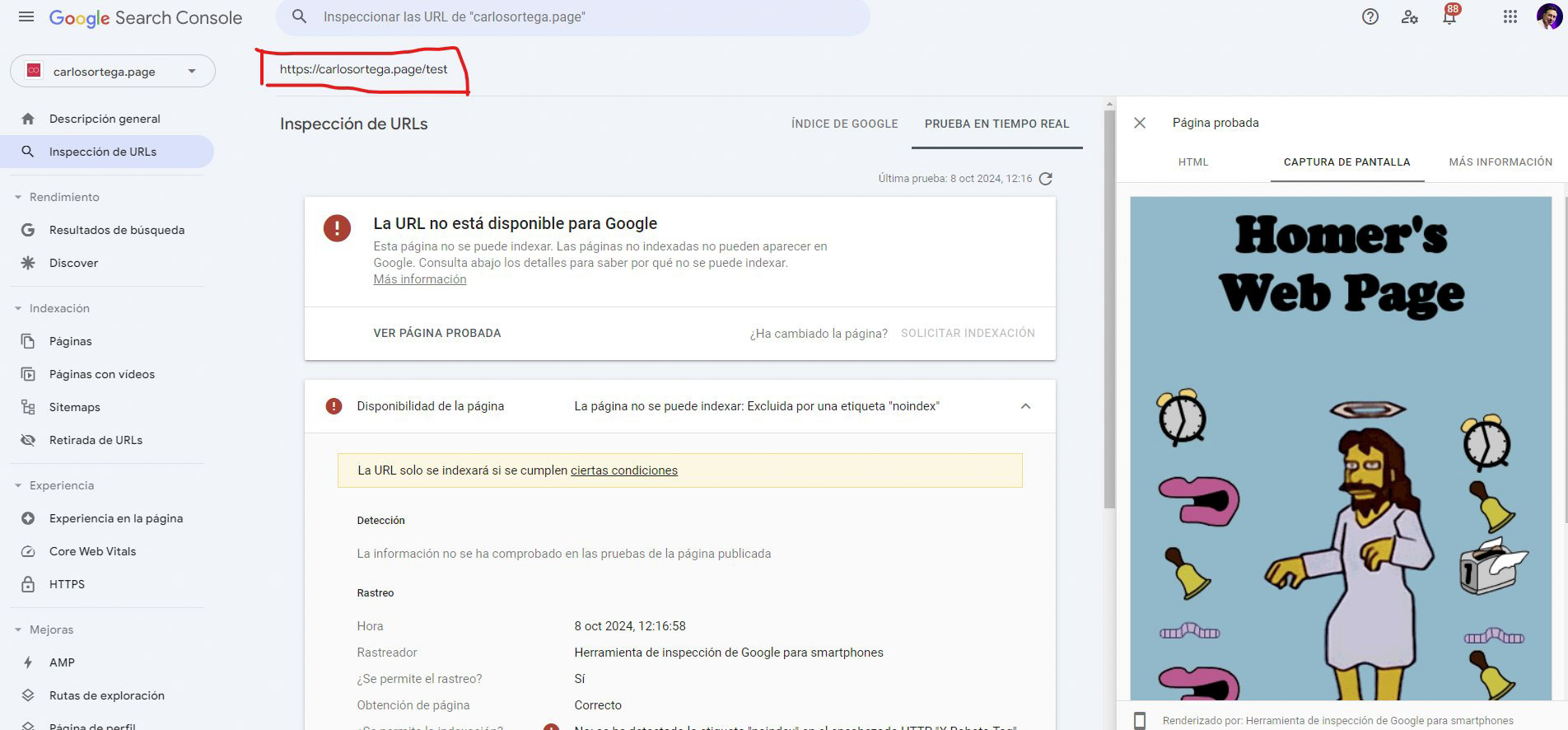
Así que mira tú por dónde mirando otra cosa hemos acabado dando con el problema. La vida ¿eh?
Su servidor está bloqueando al rastreador de Google, denegándole el acceso, por lo que sea. No es por tanto nada en el propio sitio web que pudiéramos encontrar. El problema está un paso antes, en la comunicación entre el propio servidor y el buscador.
El drama de esto es que si es algo muy temporal no pasa nada, pero si se mantiene unos días como debe estar pasando… Google empieza a desindexarlo todo. Y tiene sentido, no va a mantener en sus resultados de búsqueda un contenido al que no puede acceder para saber qué pone ni de qué trata.
En concreto, en su documentación dice literalmente de los Status Code 4XX:
Este proceso quita la URL de la indexación si ya se había indexado previamente. No se procesan las páginas 404 encontradas recientemente. La frecuencia de rastreo disminuye gradualmente.
Así que bueno, caso cerrado. Y web noqueada en dos asaltos a menos que solucione ese fallo pronto.
Conclusiones
Una vez más, nos encontramos con un caso en el que un detalle técnico supone desaparecer del buscador. Da igual tu marca, estrategia de contenidos, on-page o cantidad de enlaces externos de calidad que tengas.
Técnica.
Sin una buena base técnica lo demás no importa. Y no te engañes, nada de esto va a cambiar con la llegada de la inteligencia artificial, al revés. Puedes ver las recomendaciones para salir mejor en sus resultados aquí mismo… pura base técnica.
Así que ya sabes, mima a tu web, monitoriza todo continuamente para evitar sustos como éste y después, buen y bien formateado contenido. El resto vendrá (casi) solo.
Espero que te haya gustado este #CSIGoogle y si te ha parecido útil, o crees que puede serle útil a otras personas, te agradeceré cualquier compartido que le des en redes sociales o enlaces que le puedas poner. Y si tienes una web (o la idea de tener una) y crees que te puedo echar una mano, puedes contactarme por aquí y lo hablamos.
Un abrazo y nos vemos en el próximo artículo 🙂

Consultor SEO técnico y estratégico independiente con más de 10 años de experiencia. Divulgo contenidos en redes y he organizado eventos como Digital Jam y Clinic SEO. También soy ponente en congresos y profesor en máster y formaciones de marketing y posicionamiento web.
He colaborado con muchas de las mejores marcas nacionales e internacionales y formado a equipos de empresas como Inditex, LaVanguardia o la UAB. Jurado en diversos premios SEO internacionales y reconocido como mejor SEO de Barcelona en 2018.
2 comentarios
Pues…
Sencillamente brutal, Carlos. Te sigo en Linkedin y ahora te seguiré en tu blog.
¡Ea!
Muchas gracias por este pedazo de análisis.
Un saludo!
Manuel E.
Muchas gracias por tu comentario, Manuel ¡me alegro que te haya gustado! 😀