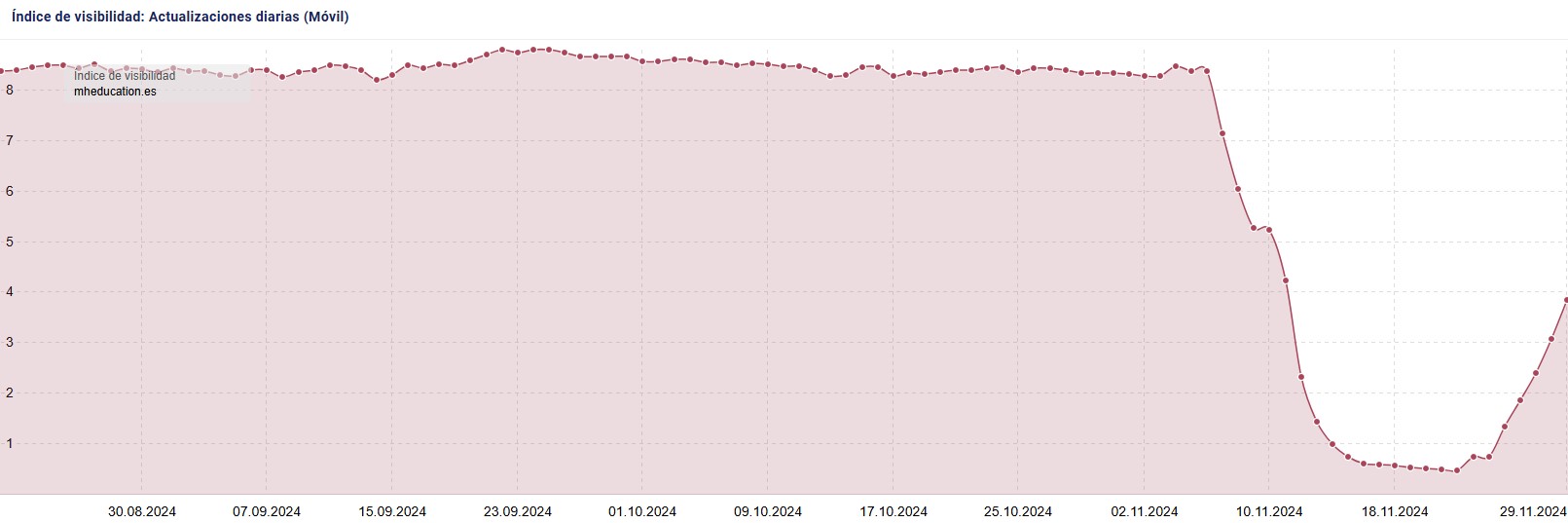
La web de libros de McGraw Hill en España está perdiendo visibilidad y tráfico online a marchas forzadas desde hace poco más de una semana ¿Qué podría estar siendo la causa? Lo intentamos descubrir en este nuevo #CSIGoogle.
Creo que todxs conocemos a la editorial de libros McGraw Hill. A lo largo de nuestra época de estudios habremos tenido seguramente más de uno de sus libros en nuestra mochila.
Poca presentación por tanto sobre ellos, vamos directamente a ver por qué últimamente podrían estar cayendo.
Lo primero como siempre es mirar si estamos buscando algún factor (probablemente) técnico. Si fuera algo algorítmico basado en alguna actualización reciente de Google en base a la ‘relevancia’ o similar… poco podremos encontrar.
Y de entrada parece técnico. Por cómo cae todo a peso por igual.
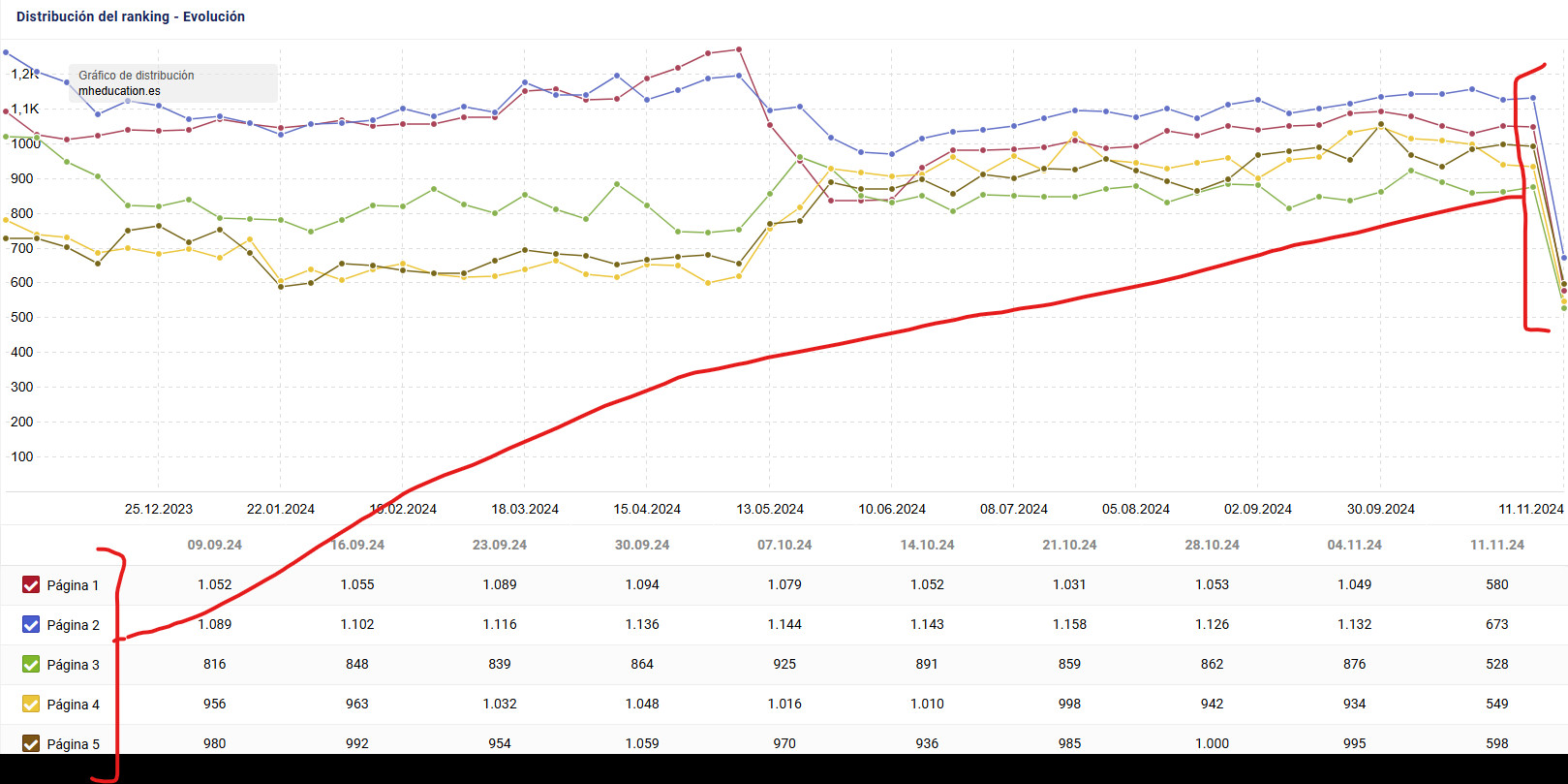
Si te preguntas cómo se vería ese mismo gráfico en caso de ser por un golpe de algoritmo, sería algo parecido a esta otra captura:
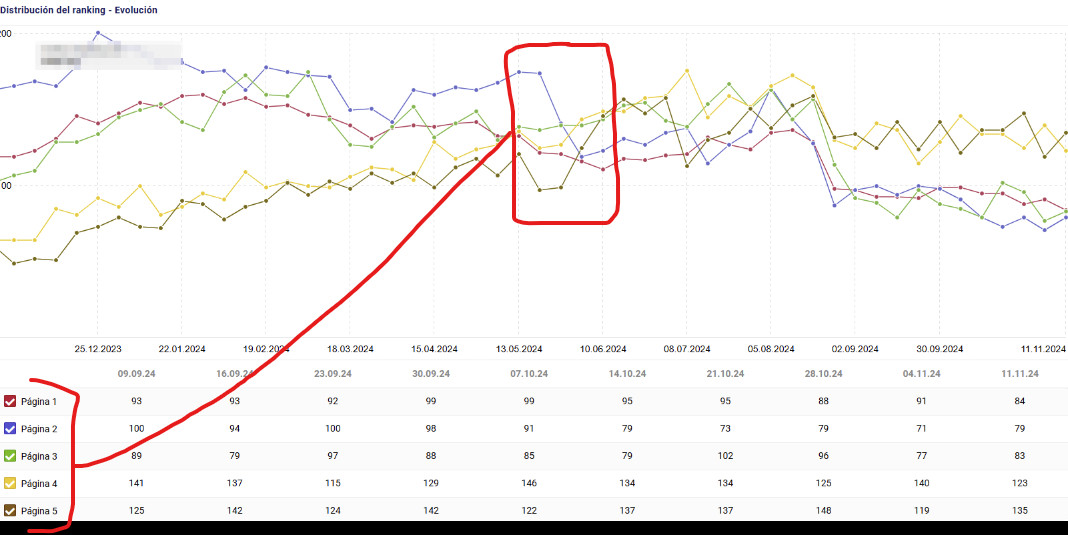
Ahí puedes ver cómo los resultados en segunda página bajan, pero son ‘rescatados’ por los de la quinta, que sube.
Empobrece el posicionamiento, pero no desaparece.
Bien, pues sabiendo que igual encontramos algo, seguimos.
El siguiente paso es ver para qué búsquedas se ha desaparecido. Y con qué URL’s. Aquí ya vemos un causante claro. Muchísimas de las palabras clave que estaban en TOP20 posicionaban PDF’s… que ya no existen.
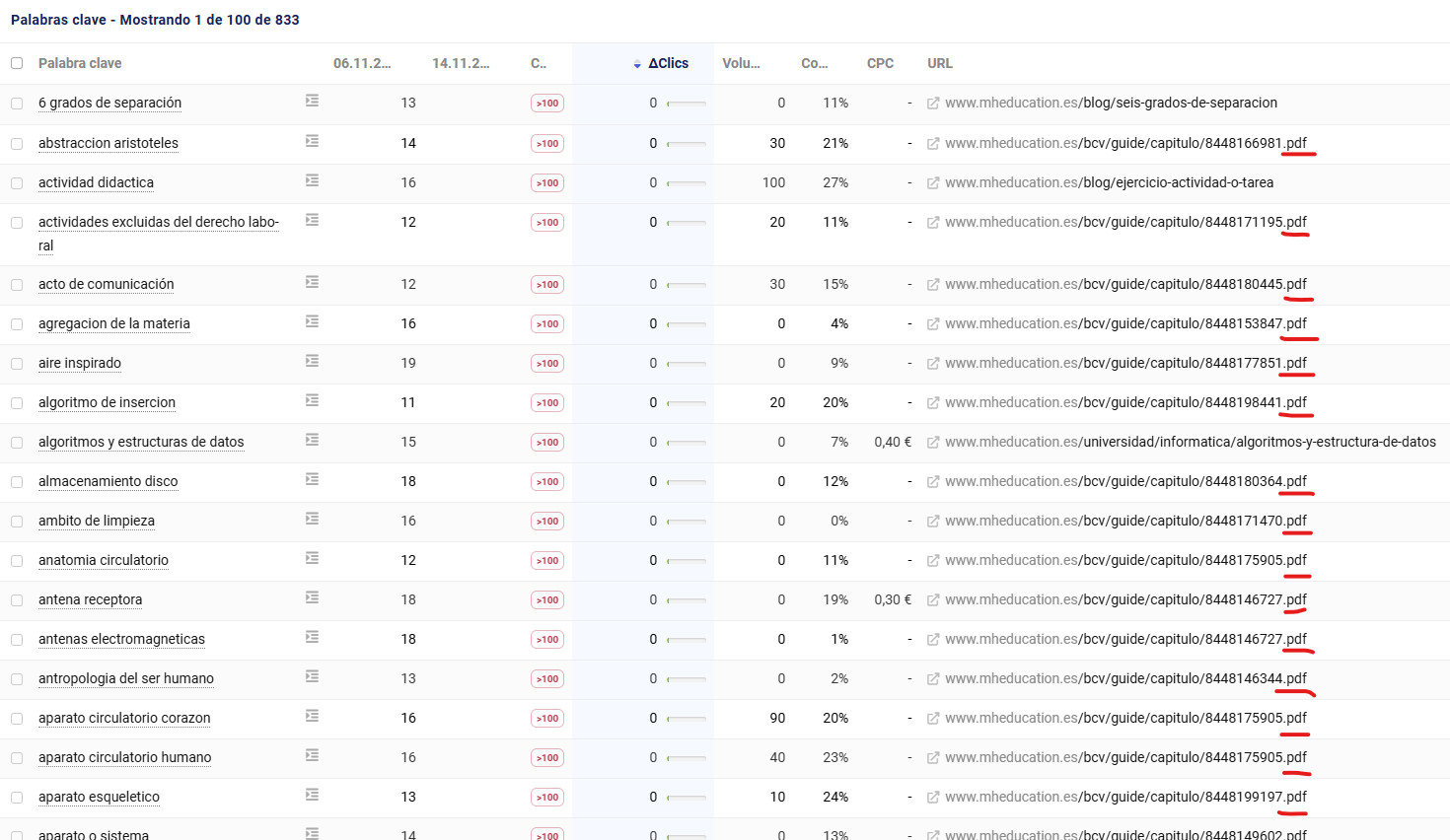
¿Por qué se han eliminado? Es algo que no podemos saber, pero es tan masivo que parece deliberado.
Al desaparecer, y responder con un Status Code 404 al rastreador de Google, poco a poco se están desindexando. Desapareciendo así toda posibilidad de posicionar con ellas.
De hecho algunas siguen indexadas, aún sin existir, pero porque es muy reciente. Es cuestión de días que también se vayan.
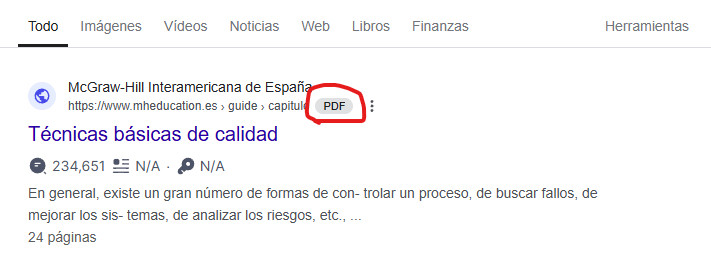
De 1.669 palabras clave que posicionaban TOP20 y han volado, 1.404 era por los PDF’s. Parece desde luego la causa principal de la caída.
Pero ¿podría haber algo más? Vamos a mirar el resto de URL’s del sitio. En el resto hay mucho blog, aunque también otro tipo de páginas.
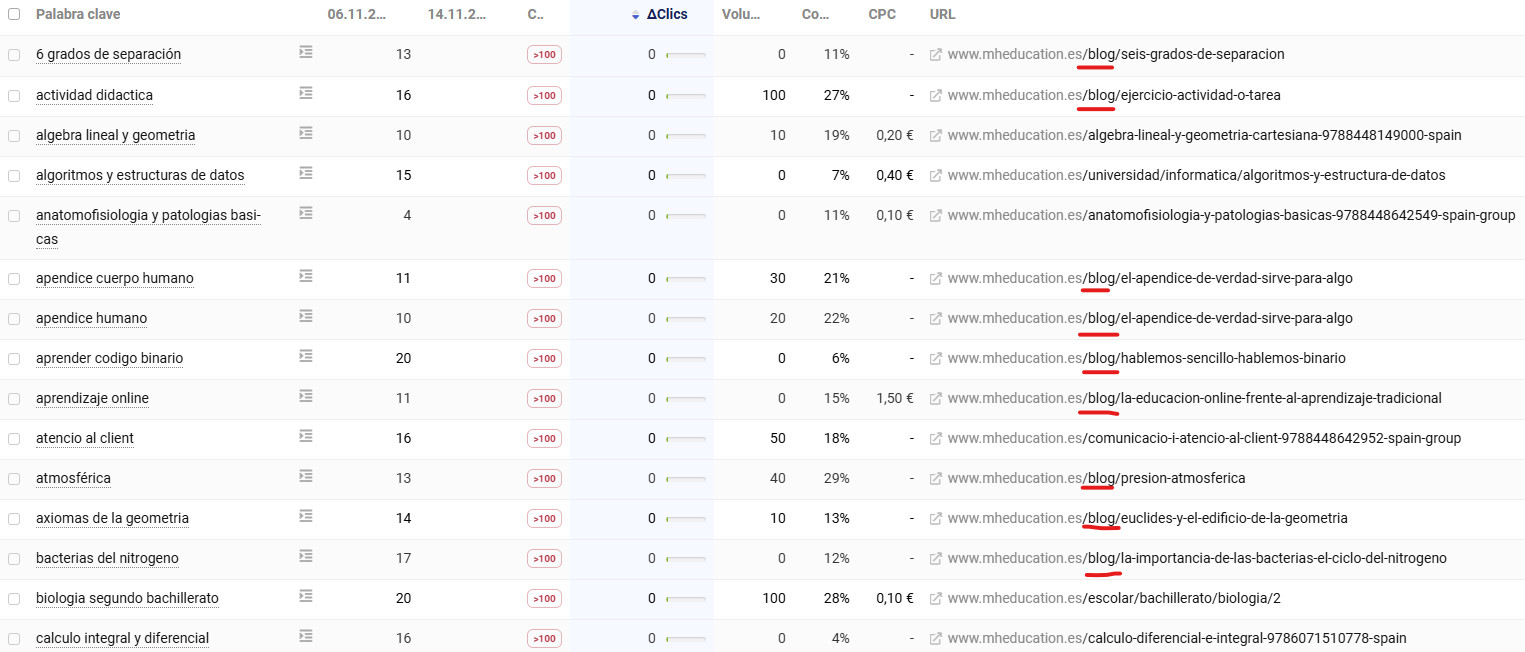
Que haya más blog que otra cosa no necesariamente quiere decir que sea un problema de los artículos en concreto. Echando un vistazo rápido vemos que hay unos 600 posts, que no son pocos, y además tienen buen contenido. Al contrario que las páginas de fichas y listados.
Posicionan por tanto mejor.
Un ejemplo de URL de blog. Buen contenido.
Las fichas y listados… ya no tanto.
La optimización on-page de las páginas es correcta como mínimo. Nada que haga pensar que pueda causar una caída tan bestia.
Son páginas indexables según la etiqueta ‘meta robots’,
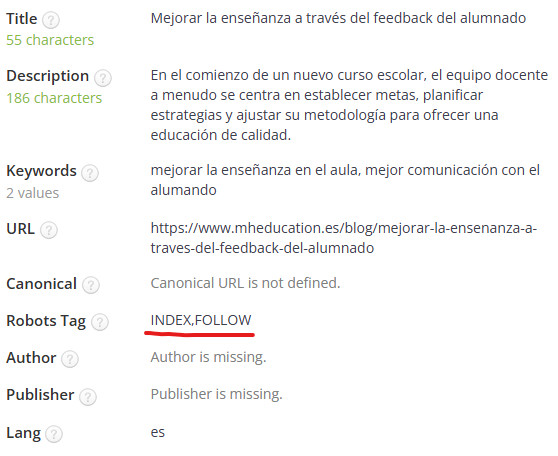
y rastreables al no estar bloqueadas desde robots.txt y renderizar su contenido correctamente.
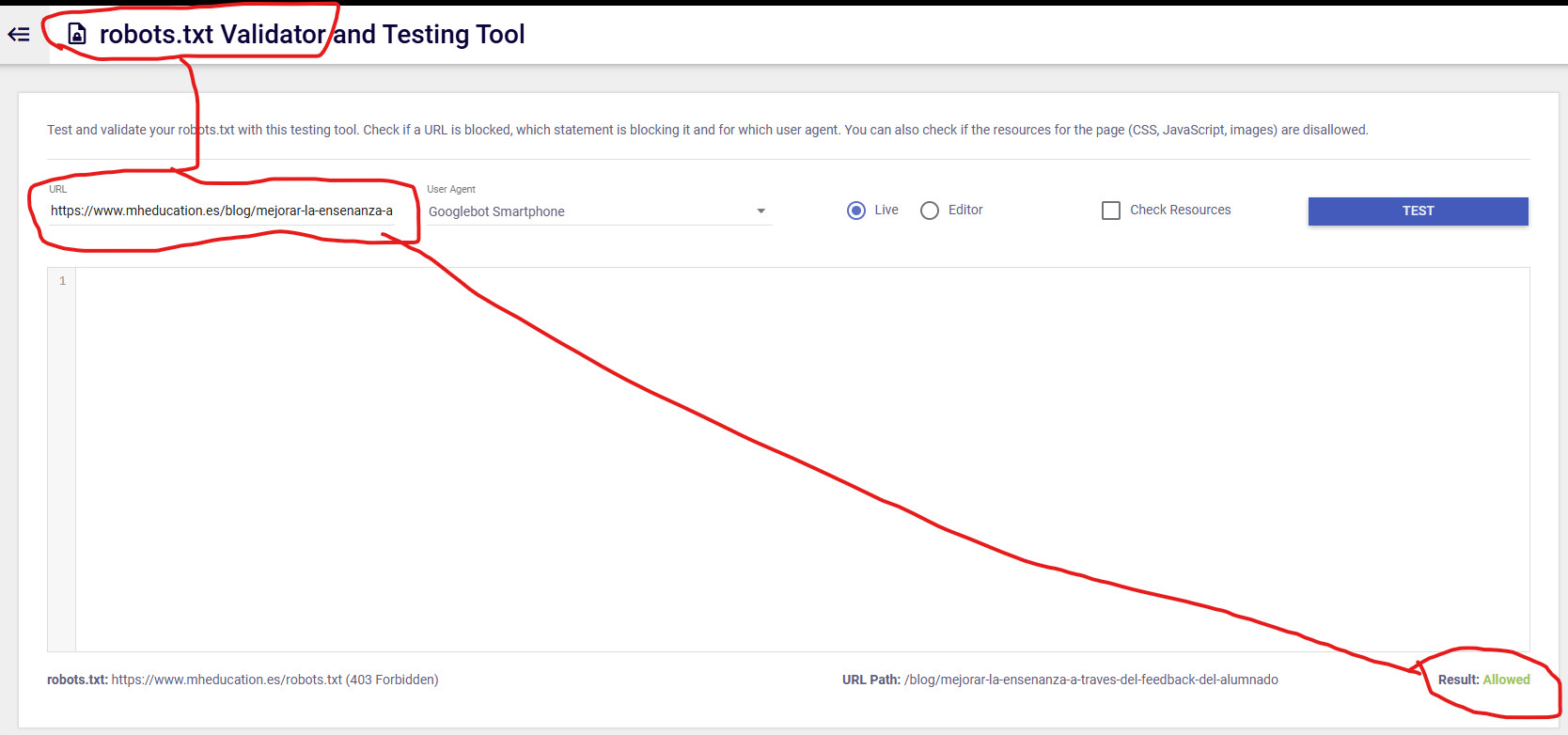
Pero un momento… ¿¿¿Qué es esto de que Google no la pudo rastrear???
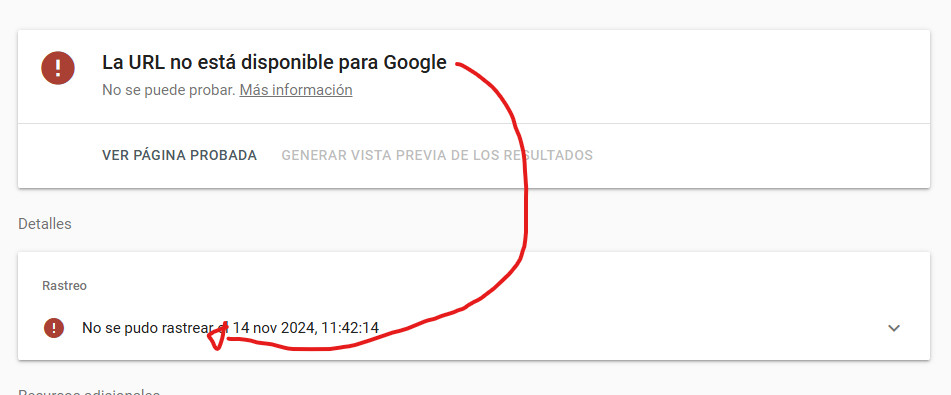
Si abrimos el desplegable para saber más, lo primero que vemos es que Google necesita mejorar este texto. Sí la ha podido rastrear, y de hecho podemos ver en el test (salía justo a la derecha de lo que aparece en la captura superior) que ha podido leer y ‘pintar’ el contenido.
En realidad quiere decir que no la puede INDEXAR… y no puede por un «X-Robots-Tag».
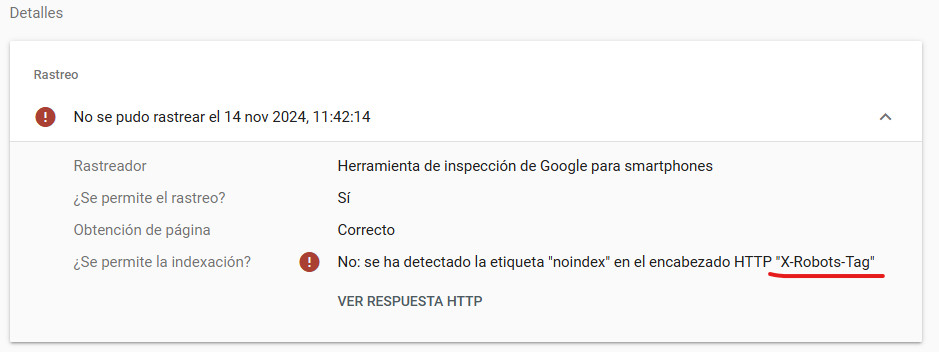
Y ‘¿Qué es un encabezado HTTP ‘X-Robots-Tag’?’ puede que este estés preguntando.
Pues es otra manera desde donde podemos decirle a Google que una URL es indexable o no.
Como la etiqueta ‘meta robots’, sólo que en lugar de mediante HTML se lo decimos con las cabeceras HTTP que envía nuestro servidor.
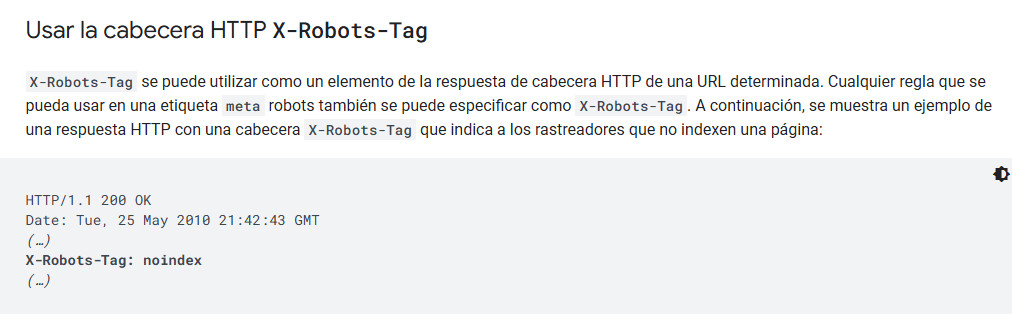
Vamos a mirarlo con una extensión de Chrome, ya que lo peor de los encabezados HTTP es que no puedes verlos de manera sencilla y… ahí lo tenemos.
Efectivamente, las diferentes páginas están diciendo a Google por un lado (HTML) que se quieren indexar, pero por el otro (HTTP) que no.
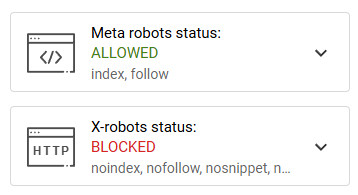
Ante la duda entre dos reglas contradictorias, Google siempre elige la más restrictiva. Por tanto: No indexables.
Eso ha hecho que a lo largo de los últimos días todas las URL’s estén desapareciendo de los resultados de búsqueda, ocasionando así la pérdida de visibilidad y tráfico. Caída que irá a más si no se corrige el error en breve.
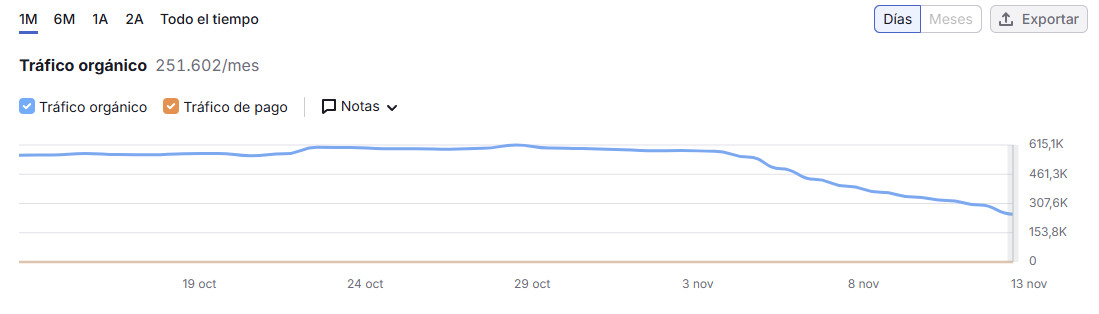
¿En qué momento se puso (entendemos que sin querer) este noindex en toda la web? No lo podemos saber, pero seguramente muy pocos días antes del principio de la caída.
Y no podemos saber mucho más por culpa de lo de archive.org…
Hace cerca de un mes la web que guarda ‘copias’ de todo Internet, pudiendo así comparar sus cambios, fue atacada. Ha podido restaurarse, pero por protección llevan desde entonces sin guardar copias de ningún sitio, así que estamos ciegos ahora mismo. Puedes ver más información aquí.

Así pues, la eliminación de cientos de PDF’s parece una causa clara de pérdida de visibilidad.
Pero poco importa, ya que de toda manera se ha marcado por error todo el site como no indexable, desapareciendo poco a poco del buscador.
Creo que sería un poco el resumen.
Espero que te haya gustado el caso. Si quieres más, los estoy intentando recopilar todos poco a poco en la categoría: CSI Google.
Y como siempre, todo compartido o comentario si crees que puede ser de interés de más gente es súper agradecido 💌
Saludos y ¡Nos leemos en el próximo post!
EDITO:
Este post está basado en el hilo de Twitter donde analicé el caso hace un par de semanas. A raíz hoy de la publicación en el blog, he vuelto a mirar la visibilidad del proyecto y está remontando a pasos agigantados:
Y es que si volvemos a mirar la URL que usé de ejemplo para confirmar que la etiqueta X-robots estaba evitando la indexación… vemos que está al fin corregida 😀

Así pues ¡Final feliz para McGraw Hill! Me alegro que lo hayan podido solucionar y, porque no decirlo, haber podido acertar en mis sospechas iniciales.
Ahora sí ¡Hasta pronto!

Consultor SEO desde 2014, a lo largo de mi carrera he liderado el SEO de grandes webs tanto a nivel agencia como inhouse y actualmente freelance.
Divulgador y ponente, también colaboro desde hace años como profesor en varios máster SEO, así como en masterclasses y cursos para diferentes plataformas.
1 comentario
Buen artículo Carlos 🙂 muy fan de tus diagnósticos queremos más jeje