Índice de contenido
- 1 Google se aleja de su misión original
- 2 Cómo funciona un LLM como ChatGPT
- 3 ‘Alucina Vecin-IA’
- 4 Cómo compensa la IA a los creadores de contenido
- 5 Cómo puede la IA compensar a los creadores (de verdad)
- 6 La solución factible, intermedia y temporal
- 7 Hacia dónde va Internet en los próximos años ¿Napster 2.0?
Wikipedia define un ensayo literario así:
El ensayo es un tipo de texto en prosa que explora, analiza, interpreta o evalúa un tema. Se considera un género literario comprendido dentro del género didáctico.
Las características clásicas más representativas del ensayo son:
- Es un escrito fundamentado que sintetiza un tema significativo.
- Tiene como finalidad argumentar una opinión sobre el tema o descubrirla.
- Posee un carácter preliminar, introductorio, de carácter propedéutico.
- Presenta argumentos y opiniones sustentadas en ideales.
Así que supongo que me dispongo a hacer un ensayo sobre el contenido en Internet y la inteligencia artificial.
Podría haber cogido la versión más reducida que me daba la IA de Google, pero es que no me ha dado la gana. Porque de eso va este post, de por qué no me parece buena idea sustituir los resultados de búsqueda tradicionales por un resultado generado por una inteligencia artificial.
Obviamente esto no deja de ser mi manera de ver el asunto ahora, abril de 2025, pero supongo que para eso tengo blog. Para escribir mis pensamientos de vez en cuando en él.
Google se aleja de su misión original
Empecemos por el principio ¿Cuál ha sido supuestamente la visión y misión de Google desde su fundación? Ellos dicen que…
Nuestra misión es organizar la información del mundo para que todos puedan acceder a ella y usarla
Vamos a quedarnos con una palabra en concreto de esa aspiración: ORGANIZAR.
 La idea era buena, extrapolar a Internet y las páginas web la revolucionaria idea de Gene Garfield a mediados del siglo XX para organizar la literatura científica de la época. Hablé en detalle de esta chulísima historia en este hilo que acabo de recordar que debo convertir en post.
La idea era buena, extrapolar a Internet y las páginas web la revolucionaria idea de Gene Garfield a mediados del siglo XX para organizar la literatura científica de la época. Hablé en detalle de esta chulísima historia en este hilo que acabo de recordar que debo convertir en post.
Repito. ORGANIZAR.
No ‘leer’ dicha información creada por otros y luego contar su versión reciclada como si hubiera hecho la propia IA el contenido. Eso implica demasiadas cosas que creo que están mal y son las que quiero intentar argumentar hoy.
Cómo funciona un LLM como ChatGPT
Todo lo que comente aquí no hace referencia únicamente a Google. También a ChatGPT, DeepSeek o cualquier otro LLM (Large Language Model). Pero fue Google el que, en contra del pensamiento popular, inició todo esto al sacarse de la chistera los Transformers en 2017.
No fue ChatGPT. Ellos solo fueron más listos y les adelantaron por la izquierda aprovechándose de su propio invento.
Vamos a intentar simplificar al máximo cómo funcionan estos LLM para no irnos por las ramas.
Imagina un robot rastreador que se lee tooooooooooodo el contenido que encuentra en Internet. De todo ese contenido extrae cada una de sus palabras, y a cada una le asigna un número exclusivo. Ese número es un ‘token’, y dicho proceso ‘tokenizar‘.

Captura extraída del canal de YouTube de Leon Petrou
¿Qué hace después con todo eso? Va a poner todos esos números (tokens) en una gráfica y así verá qué palabras suelen estar juntas, cuáles tienen patrones tan similares que podrías asegurar que significan lo mismo o al revés, que son antónimos. O si una palabra parece la misma pero cambiando el número o el género, el mismo verbo en otra forma o mil cosas más.
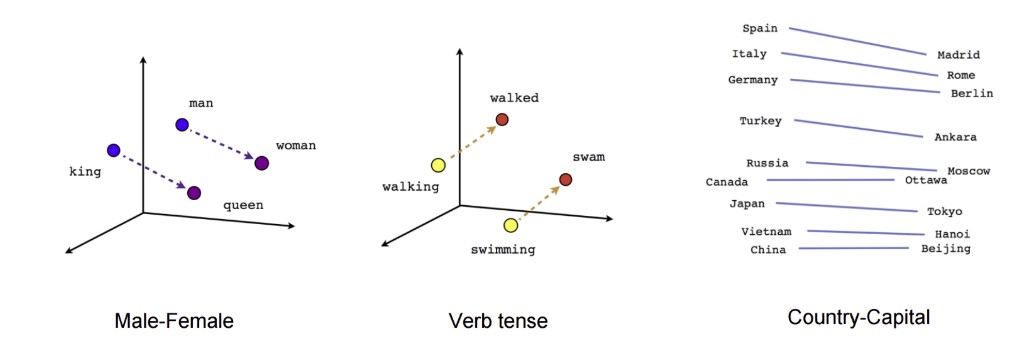 Este proceso también le ayudará a saber que una palabra puede tener un significado u otro dependiendo del contexto, desambiguando así conceptos.
Este proceso también le ayudará a saber que una palabra puede tener un significado u otro dependiendo del contexto, desambiguando así conceptos.
Como ‘banco’. Puede ser algo donde sentarse en un parque. Un conjunto de peces. O un lugar donde guardar tu dinero. Depende.
 Aquí te lo explica el propio Google de manera muy sencilla:
Aquí te lo explica el propio Google de manera muy sencilla:

TOTAL. Que en realidad el LLM tiene un montón de información y palabras pero no entiende nada.
Sólo sabe que unas palabras suelen ir más o menos cerca de otras. Y en base a eso, cuando tú le preguntas algo, hace sus cálculos y te junta unas cuantas en lo que considera que estadísticamente deba ser una buena respuesta.
A veces acierta. Otras alucina.
‘Alucina Vecin-IA’
¿Quieres ver un ejemplo? El otro día le pregunté a Google si sabía quién era mi amigo Maxi Portes, del e-commerce Vitamina Jota.
Ok, pues resulta que muestra una AI Overview (resultado con IA) y me dice que no solo es vendedor del mejor jamón ibérico del país, si no que es consultor SEO ¡y tiene hasta su propia newsletter!

Naturalmente, Google estaba flipando. Así que ya me picó la curiosidad y me puse a investigar las fuentes de las que decía que había cogido la información.
Y encuentro que una es una entrevista que le hicieron hace tiempo y que me lleva al final de la publicación donde pone… la biografía de David, el compañero que le había hecho la entrevista.
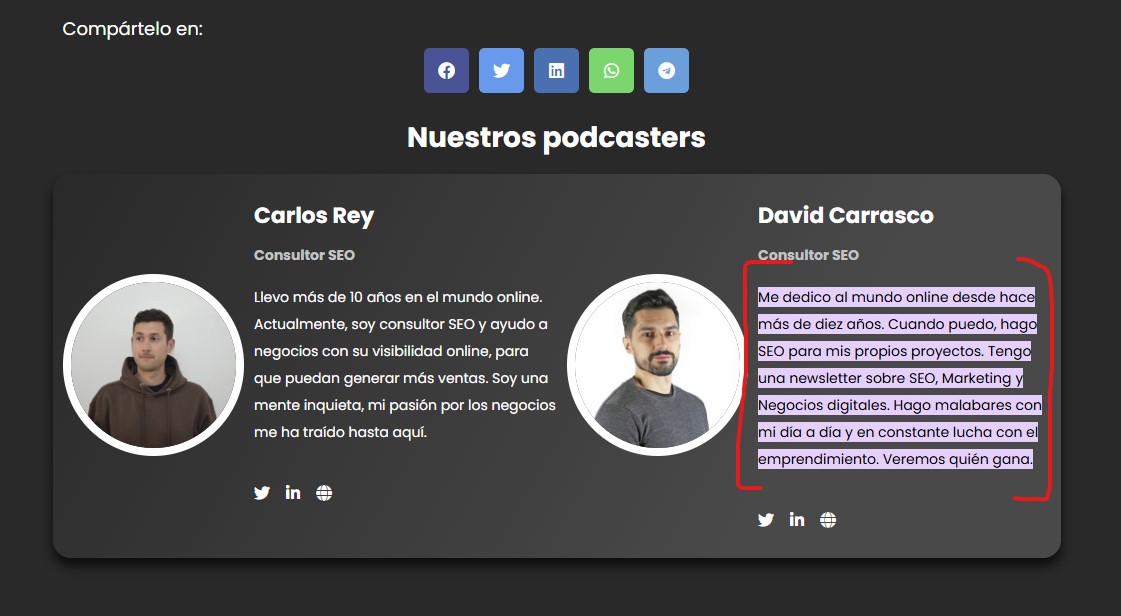
Estaba mezclando churras con merinas. Alucinando.
Pero vamos, que ChatGPT y el resto hacen lo mismo. Le pedí a este último que me diera el listado de canciones del disco ‘La Ley Innata’ de Extremoduro. Solo acertó la primera, el resto son de otros discos. Un desastre.
Mejor disco de rock nacional de este país por cierto, si me preguntan.
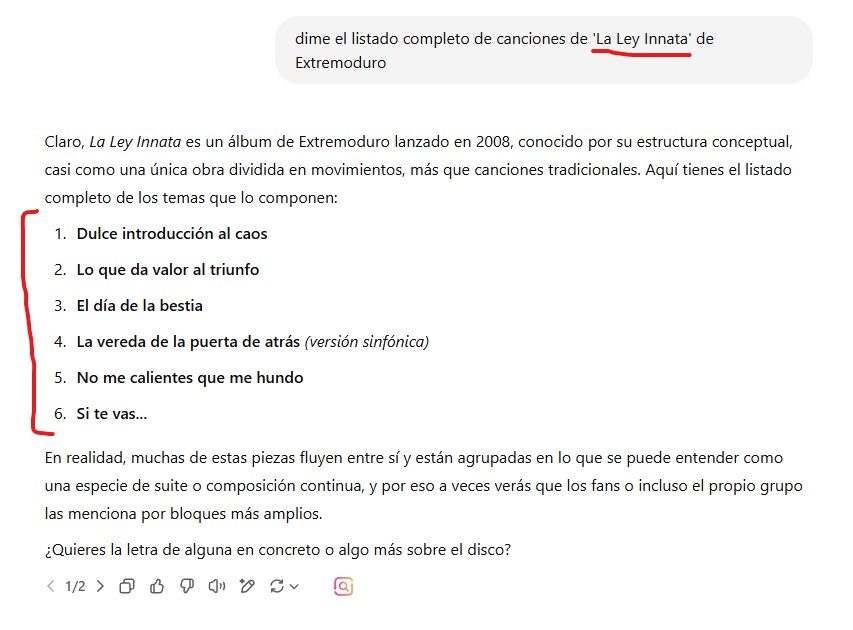
Debe ser una edición del disco especial para IA
Con todo esto quiero decir que a día de hoy ni siquiera es ya entrar en el debate de si es ético o no robar de esta manera el contenido a sus creadores. Es que además en muchas ocasiones lo pervierten, dando informaciones erróneas de manera tan convencida que puede llevar al usuario a dar por buenas auténticas burradas.
Es un claro paso atrás como alternativa al Internet que conocemos hasta ahora. Que no es perfecto, pero es mejor.
¿Por qué? Aquí creo que está la clave. Porque ahora también hay información falsa, pero al tener un listado de opciones donde elegir, creo que es fácil ver varias y sacar conclusiones. Con una respuesta única… la cosa es diferente.
Cómo compensa la IA a los creadores de contenido
Bueno ¿Y cómo ‘agradecen’ estas IA a toda esa gente, diarios o incluso escritores el absorber por la cara toda esa información con la que se entrenan y enriquecen a diario?
Dicen que les enlazan como fuentes para que así el usuario vaya igualmente a sus webs y no pierdan tráfico. Que bueno, la realidad es que muchas veces ni eso. Como en este resultado, donde ChatGPT no lista ni una sola fuente:
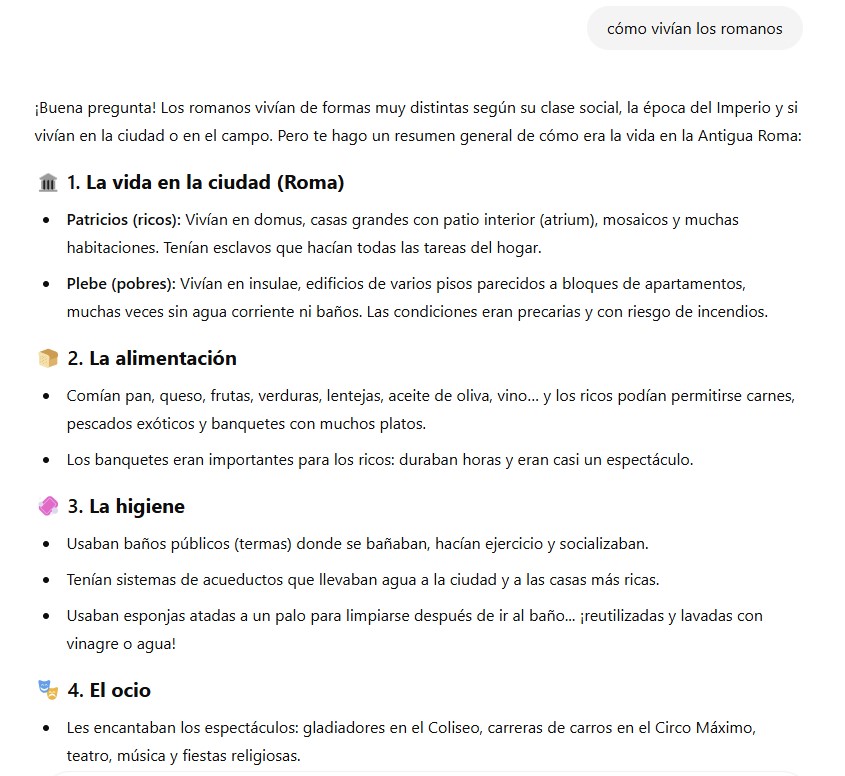
Las fuentes son los padres
Pero es que poner dichos enlaces ni siquiera es realmente compensar nada, más bien intentar al menos pasar desapercibido. De todas maneras… ¿tú harías mucho clic en estos enlaces de la imagen?

¿Y en estos otros de las AI Overviews de Google? Es cierto que en este caso también hay un módulo al lado donde se ven más, pero de forma totalmente descontextualizada ya que no sabes qué ha cogido de qué fuente y así considero que no tiene demasiado sentido hacer clic en ningún enlace para profundizar.
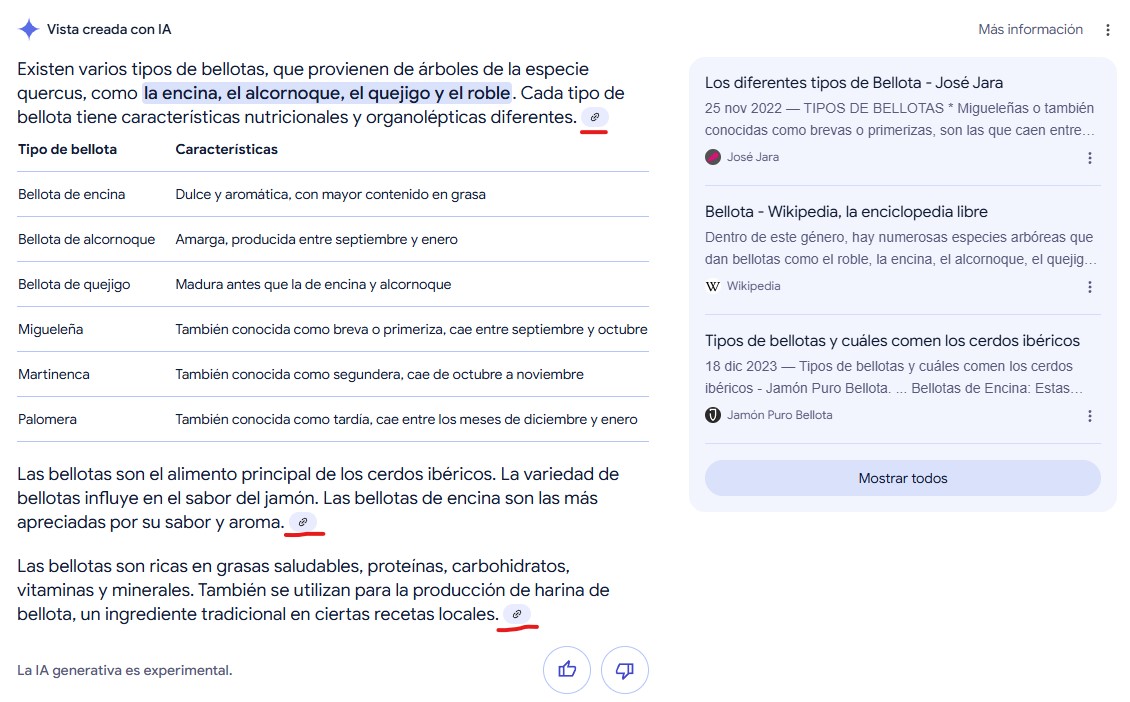
Bueno, pues efectivamente, ni tú ni nadie va a hacer clic por norma general en esos enlaces. Porque ni se ven apenas ni tienen un diseño que te incite a usarlos. Y ahí están ya algunos estudios que demuestran su afectación a la pérdida de tráfico en muchas webs.
Podemos afirmar por tanto que como compensación, actualmente, es más bien una absoluta tomadura de pelo.
Al menos en el caso de Google no me ha sorprendido. Ya hace más de dos años le comentaba a un compañero cómo creía que lo implementarían llegado el momento:

Cómo puede la IA compensar a los creadores (de verdad)
Todxs tenemos claro que la base de Internet por tanto son los creadores de contenido.
Sin contenido original no hay base de conocimiento que ninguna IA pueda leer y almacenar para generar respuestas y resultados.
Y sin embargo, si un usuario hace un búsqueda en ChatGPT y con esa respuesta ya queda satisfecho no entrará en ninguna web. Y ya acabamos de ver que aunque quiera saber más, el sistema actual de citado de fuentes está lejos de ser una solución para derivar y poder mantener el tráfico.
Sin tráfico, esa web (creadora original) no puede obtener beneficio alguno por su esfuerzo. No importa si éste venía a través de publicidad, enlaces de afiliados, muros de pago o lo que sea ¿Cómo pagará entonces las facturas?
Tal como lo veo por ahora, la única solución a esa pérdida de tráfico pasaría porque las empresas de estas IA paguen a dichas webs por poder aprovecharse de su contenido. Y de aquí salen tres opciones.
Pagan a todos
¿Suena bonito verdad? Bueno, más que bonito suena justo. Casi tanto como imposible, por supuesto.
Para tener cuanta más información mejor, más completa, más actualizada, desde más puntos de vista… necesitas el máximo de fuentes disponibles. Y esas fuentes merecen una compensación por hacer el trabajo de investigación y redacción del que después las AI Overviews de Google, ChatGPT y el resto se aprovecharán.
Pero pagar a millones de webs es poco más que una utopía, con lo que podemos descartarlo a día de hoy.
Se me ocurre intentar replicar el método actual de la publicidad programática o Adsense, donde las webs reciben más dinero en proporción a la cantidad de impresiones y clics que reciben sus anuncios, pero adaptándolo a los bots de rastreo de las IA.
Cuanto más me rastrees, más me pagas.
Sin duda, serían las mejores noticias.
No pagan a nadie
Si las webs aportan su esfuerzo y contenido y no tienen beneficio, o bien cierran el negocio y dejan de ser una fuente para la IA, o bien siguen activas pero prohiben el acceso a su contenido a los LLM mediante el archivo robots.txt u otros métodos más ingeniosos.
En ambos casos, las IA (y sus usuarios) pierden esas fuentes de contenido original. También Internet en general si cierran.
Malas noticias.
Pagan solo a algunos
En éstas, en realidad, ya estamos. Al menos en parte.
Hace un año, el Grupo Prisa (EL PAÍS, As, el HuffPost…) cerró un acuerdo con ChatGPT para permitir que este último accediera libremente a sus noticias. Pego una parte del comunicado donde lo explican:
Permitirá a los usuarios de ChatGPT interactuar en torno a la actualidad con los contenidos de alta calidad de PRISA Media en español y de Le Monde en francés. Contenidos que también contribuirán, a la vez, a la formación y mejora continua de los modelos de inteligencia artificial.
Supongo que no te sorprenderá saber qué pasa si hoy le pides al LLM que te diga las noticias del día: todo son resultados de Grupo Prisa. Pero les da igual, porque ya han cobrado por permitirlo.
Bueno, también hay un enlace de Wikipedia, pero es que la pobre es la madre de Internet.

¿Qué problema veo a esto? Pues uno igual de preocupante que el del robo de contenido. Los sesgos.
Cuando yo me entero de que ha pasado algo en política, o en deporte, no miro solo un diario. Miro unos cuantos. De izquierdas y de derechas. Y saco la media para mi conclusión final, porque aquí todo el mundo barre para casa y más en un Internet donde muchos dependen de ayudas o inversiones externas para poder seguir adelante. Y esas se pagan.
Que un LLM como ChatGPT, por seguir con el ejemplo de antes, pueda llegar a publicar sólo la versión socio-economico-politica-religiosa de las noticias desde un solo prisma… me parece peligroso.
Voy a poner un ejemplo. Un poco polémico quizás, pero muy claro.
Yo soy de Barcelona, muchos lo sabéis.
Bien, pues si tuviera que saber cómo se vive aquí en base a lo que se dice desde Madrid hace una década… habría salido corriendo.
Y contra todo pronóstico, vivo muy bien y sigo enamorado de mi ciudad. Ni me han apuñalado ni nada en más de 40 años, gracias.
Así pues, limitar el conocimiento de Internet a un sólo grupo reducido de webs con las que se llegue a acuerdos me parecería la peor de las noticias.
Y por desgracia, de las tres opciones con esta solución del pago por uso de contenido es de largo la que veo más posible. Porque sí, hasta ahora les ha salido gratis… pero porque todo esto es muy nuevo, y por tanto no hay reglas. Es el Salvaje Oeste. Pero al final habrá que sacar la cartera y no habrá dinero para todos.
La solución factible, intermedia y temporal
Creo que la solución más sencilla por ahora para hacer que los resultados con IA y los creadores convivan de la mejor manera que puedan pasa por al menos hacer un esfuerzo REAL de las primeras por derivar tráfico a las segundas.
¿Cómo? Pues justo ayer lo comentaba con varias compañeras en el Search Central Live de Madrid. Les decía que si tanto estaban defendiendo en las charlas que querían enviar tráfico, que pusieran enlaces como si fuera un artículo. Esos sí son enlaces que se ven e incitan a hacer clic.
Pues oye… ¡Ni 24 horas después parece que lo están probando! Déjame un comentario y te tiro las cartas.
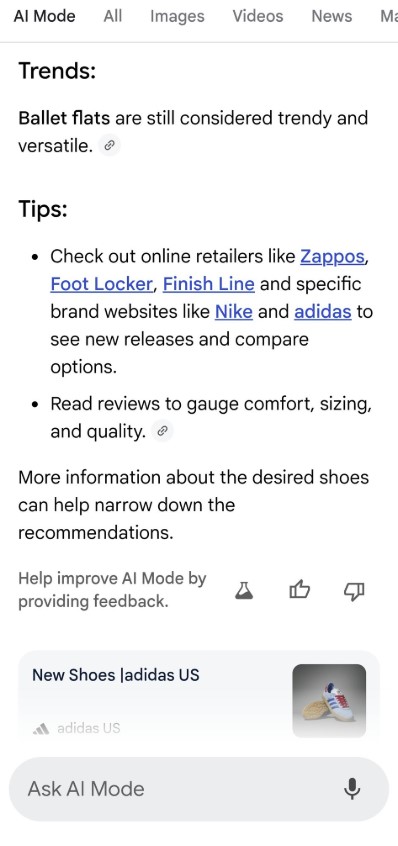
¡Esto es otra cosa! Déjalo así, Google.
Tal vez no sea la solución ideal, pero sí un buen paso intermedio.
Hacia dónde va Internet en los próximos años ¿Napster 2.0?
Bueno, pues como diría el meme:
 Pero los más antiguos recordamos bien una situación similar, pero con la industria musical: Napster, Kazaa , eDonkey, eMule…
Pero los más antiguos recordamos bien una situación similar, pero con la industria musical: Napster, Kazaa , eDonkey, eMule…
Sobre el año 2000 y en plena irrupción de Internet, descargarse canciones y películas era tan obvio y sencillo que parecía increíble. Pero claro, eso no iba a durar para siempre, porque era ilegal. Pero como he dicho antes, era el Salvaje Oeste. Costó años, pero se solucionó.
Creo que algo así pasará con todo esto de los LLM. Hay que regularlo, porque parece increíble que algo tan ilegal se haga con tanto descaro.
Y entonces las cosas serán diferentes, porque se deberá llegar a un sistema de compensaciones económicas que no haga implosionar el ecosistema online.
¿Cuáles serán esas soluciones? No lo sé. Pero ahora mismo y como he comentado, las dos más obvias me parecen:
- No molestar (no hacer perder tráfico a los creadores)
- Compensar (pagándoles a cambio de la pérdida de tráfico/ingresos)
Y eso estará regulado por leyes. O eso espero.
Porque todo lo que no sea eso deriva sí o también en:
- Webs cerrando por falta de ingresos o visibilidad.
- Webs ocultando su contenido y convirtiéndose en plataformas de pago para quien quiera leerles.
- Menos contenido para el usuario de buscadores.
- Peores resultados a través de IA, que solo pinta contenido en base a probabilidades matemáticas.
- Todavía peores resultados al degradarse las bases de conocimiento de la IA tras alimentarse de su propio contenido cada vez más frecuentemente.
Mientras tanto, creo que bien haría Google en no intentar ser ChatGPT y ChatGPT en no intentar ser Google. Son herramientas increíbles pero que creo deberían complementarse y no intentarse pisar.
Google, sigue intentando organizar Internet, no crearlo. Para eso estamos los creadores.
Y ChatGPT (y resto de LLM), intenta ‘simplemente’ ayudarnos a crear más y mejor de manera más rápida. No ser Google.
No es poco.
Sólo hay una cosa peor que informarse con una única respuesta potencialmente sesgada. Hacerlo con una que además es mentira a causa de la alucinación de una IA que no entiende lo que te está contando.


Consultor SEO técnico y estratégico independiente con más de 10 años de experiencia. Divulgo contenidos en redes y he organizado eventos como Digital Jam y Clinic SEO. También soy ponente en congresos y profesor en máster y formaciones de marketing y posicionamiento web.
He colaborado con muchas de las mejores marcas nacionales e internacionales y formado a equipos de empresas como Inditex, LaVanguardia o la UAB. Jurado en diversos premios SEO internacionales y reconocido como mejor SEO de Barcelona en 2018.
2 comentarios
Qué feo me parece que este pedazo de post no tenga ningún comentario, me alegra ser el primero 😉
Como siempre, gran análisis Carlos!
Me parece que este contenido va a envejecer muy bien, porque no has fallado ni una.
Gracias infinitas por compartir tus conocimientos y análisis, siempre se sacan nuevas ideas y puntos de vista interesantes.
Abrazo!
Muchas gracias, Bruno 🙂