Índice de contenido
Google cambia continuamente, y es cada vez más frecuente ver que en sus resultados de búsqueda aparecen todo tipo de carouseles, paneles, resultados instantáneos o fragmentos destacados conviviendo con nuestro añorable TOP10 de resultados ‘normales’.
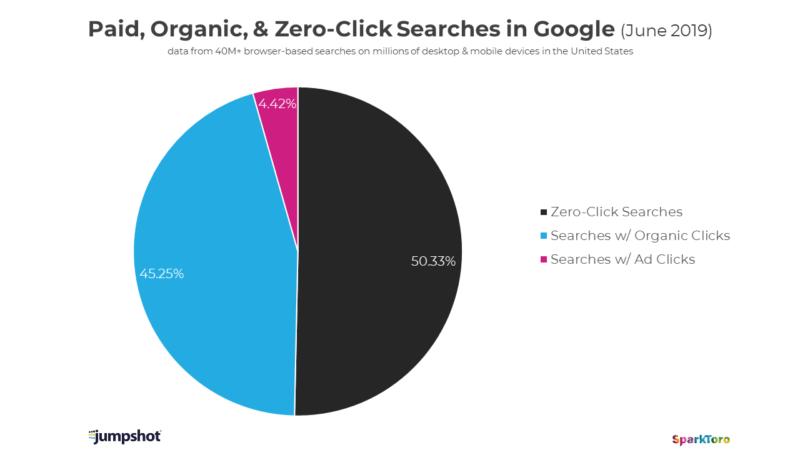
Algunos de estos módulos no aportan tráfico a ninguno de los resultados al dar Google una respuesta directa al usuario que hace innecesario hacer clic en ningún otro sitio. Este tema está acabando con muchos verticales como webs de letras de canciones o climatología por poner algunos ejemplos, ya que la cosa está llegando al punto en que más del 50% de las búsquedas acaban sin clic, como se pudo comprobar en el estudio de este verano de SparkToro.
Hay otro tipo de módulos sin embargo que sí muestran contenido y enlaces a webs de terceros. Y decir que estos nuevos módulos son un problema para el tráfico de un proyecto que posiciona en una URL del TOP10 es tan cierto como que pueden darte un push importantísimo si logras salir en ellos. Con lo que es importante saber cuáles son los que aparecen en cada uno de los casos para optimizar nuestro contenido y estrategia en base a ello.
La pregunta es ¿cómo podemos saber qué modulo o módulos salen en las diferentes pongamos… 5000 palabras clave por las que posiciono o me interesan?
Encontrando los footprints
Dándole vueltas a eso, he estado una temporada buscando manualmente keywords y más keywords intentando sacar todo tipo de módulos en los resultados, y una vez sacados unas 5 veces cada uno, he intentado encontrar un ‘footprint’ único en cada uno de ellos que le diferenciara del resto.
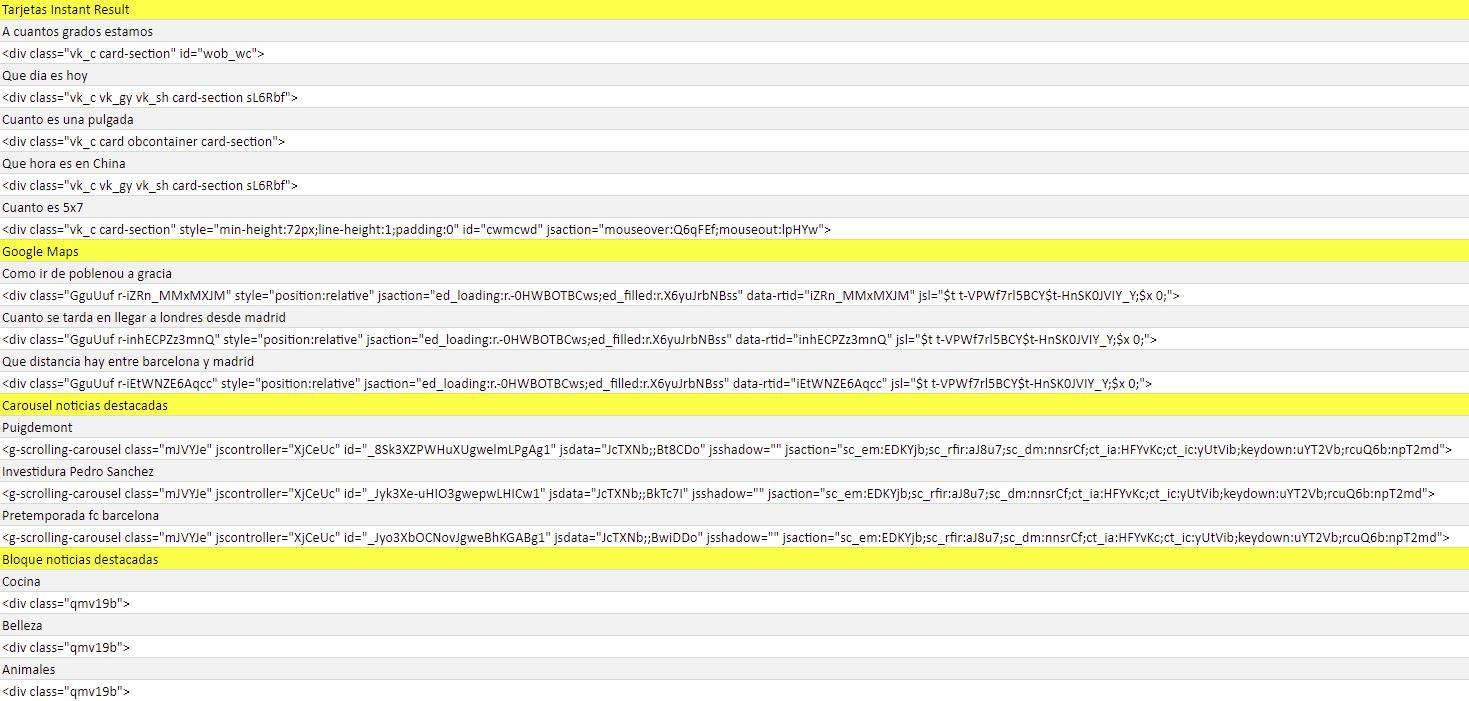
Buscando ‘footprints’ a manija 😀
El resultado fue un listado de más de 30 módulos de Google de toda clase en los que incluí todo lo que vi: Google Ads, carouseles, búsquedas relacionadas, packs de mapa local, knowledge panels… cualquier cosa que pudiera quitar clics al TOP10 orgánico. El listado completo (por ahora) quedaría así:

Generando las URL’s de resultado de Google
Una vez tuve dichos ‘footprints’ lo que necesitaba era poder rastrear los diferentes resultados para cada una de las keywords. La manera más sencilla era coger una URL de ejemplo, ya que Google siempre las construye igual, y mediante concatenaciones con Excel montar el resto automáticamente.
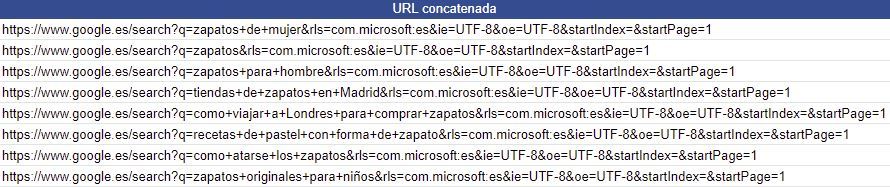
Así, para la palabra clave ‘zapatos de mujer’ (por ejemplo), la URL de resultado sería:
https://www.google.es/search?q=zapatos+de+mujer&rls=com.microsoft:es&ie=UTF-8&oe=UTF-8&startIndex=&startPage=1
Por tanto, la fórmula en este caso era:
https://www.google.es/search?q= + keyword (espacios convertidos en +) + &rls=com.microsoft:es&ie=UTF-8&oe=UTF-8&startIndex=&startPage=1
Esta manera de construir URL’s por parte de Google he podido comprobar que varía en función de varias cosas, pero lo importante es tomar una de ejemplo y replicarlo.
En todo caso, el primer paso es tener el listado de palabras clave que queramos en Excel y hacer un sencillo ‘Buscar y Reemplazar’ en toda la columna donde sustituiremos todos los espaciados por un ‘+’.

Una vez tenemos esto, ponemos una columna antes y otra después de la columna de keywords con los trozos de la URL de resultados de Google, así:

Y con eso listo, sólo quedaría concatenar las tres columnas en una sola para tener las diferentes URL’s de resultado listas.
Rastreando y consiguiendo resultados con Screaming Frog
Muy bien, pues con las dos grandes piezas listas, footprints y URL’s generadas, queda ponerse manos a la obra. Para ello utilizaremos nuestro querido Screaming Frog.
Aquí tendremos que configurar algunas cosas antes de empezar a rastrear:
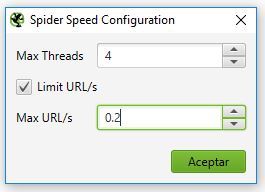
En Configuration > Speed bajaremos la velocidad y simultaneidad de rastreo para evitar ser bloqueados por Google al poco de empezar y quedarnos sin resultados. Obviamente va más despacio de lo normal. Sin prisa pero sin pausa. Yo lo configuro como en la siguiente imagen y hasta ahora no he tenido problemas:
En Configuration > User-Agent cambiaremos el que viene por defecto de Screaming Frog por Chrome. Este paso es importante porque si no la cosa no funcionará.

Por último iremos a Configuration > Custom > Search y pondremos los footprints de los módulos que queramos investigar en los diferentes campos de ‘Filter’. Aquí el problema a día de hoy es que como he dicho, he detectado unos 30 y Screaming Frog sólo nos permite un máximo de 10 footprints a la vez. Nada que no se solucione con un par de pasadas más.
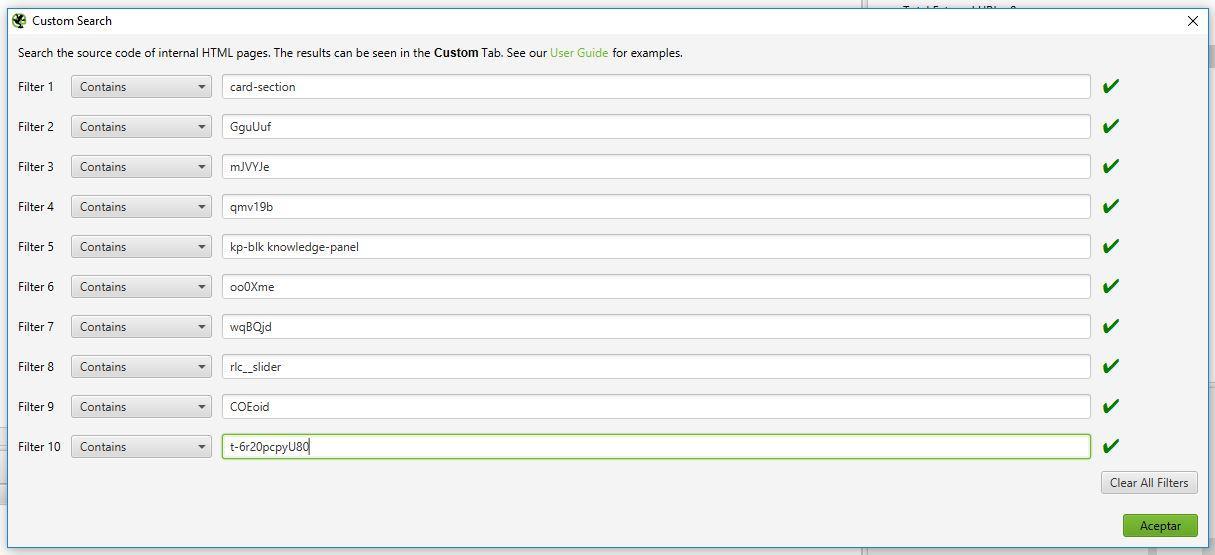
Una vez configurado, ponemos Screaming Frog en modo lista (Mode > List) y subimos todo el listado de URL’s de resultado que habíamos generado antes desde Upload > Enter Manually…
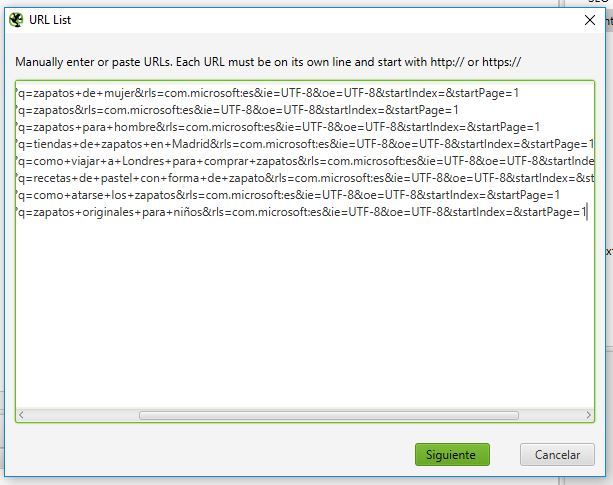
Y… ¡A rastrear!
Cuando Screaming Frog termine, en los diferentes ‘Custom Search’ aparecerán listadas algunas de las URL’s. Por lo tanto, las que salgan en el footprint de carousel de imágenes… pues son las que tienen ese módulo en su lista de resultados. Así con todas.
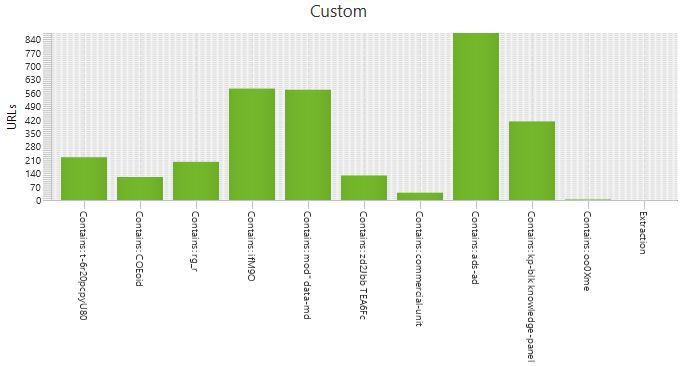
Para presentar toda esta información en un Excel de manera más visual, lo mejor es copiar y pegar los listados resultantes en diferentes pestañas o columnas. Cada pestaña o columna sería por ejemplo ‘Carousel de imágenes’ y la lista de URL’s correspondiente, ‘Mapa local’ y lo mismo…
Así, con eso preparado, sólo tendremos que hacer un panel en la pestaña principal donde lanzamos un BUSCARV de cada una de las diferentes URL’s en los listados y tendríamos algo así:

Conclusiones y aplicaciones
Ok, listo. Y ahora lo más importante… ¿y para qué quiero yo saber esto?
Bueno, las posibilidades son bastantes. Por poner algunos ejemplos, tal vez veas que en según que resultados aparece siempre el mapa local con negocios, lo que implicaría que esa keyword está geolocalizada y a lo mejor no tiene sentido esperar por tanto salir por ella desde sitios alejados de tu área. Tal vez salgan siempre carouseles de vídeo… ¿por qué no pensar una buena estrategia de contenidos en YouTube para intentar salir ahí? ¿Salen productos de Google Shopping? Seguramente Google trate a esa keyword como transaccional y tiene más sentido atacarla en una ficha de producto que en un artículo del blog.
Hacer un análisis de este tipo de manera periódica también puede mostrarnos bloques que antes no aparecían y ahora sí lo hacen, explicando así subidas o bajadas repentinas de tráfico en nuestra web.
Como ves, es un tema que da bastante juego e información que puede perderse sin tener conocimiento de qué sale o qué no.
Y ya está, como decía, mi intención es ir actualizando este listado de footprints (y este post) con futuros módulos que Google vaya lanzando en las SERP’s. Con lo que si sabes de alguno que falta o detectas nuevos ¡no dudes en escribirme por aquí o por Twitter! 🙂

Consultor SEO desde 2014, a lo largo de mi carrera he liderado el SEO de grandes webs tanto a nivel agencia como inhouse y actualmente freelance.
Divulgador y ponente, también colaboro desde hace años como profesor en varios máster SEO, así como en masterclasses y cursos para diferentes plataformas.
23 comentarios
Muchas gracias Carlos por compartir este post, acabo de leerlo desde el móvil y ya lo tengo marcado para releerlo con tranquilidad en la oficina. Pero las posibilidades son brutales.
¡Me alegro que te parezca útil Santiago! Lo dicho, si crees que falta algún módulo que tengas controlado dímelo y actualizo la lista de footprints 😉
¡Saludos!
Impresionante! Me ha llegado tu post, ya que yo no te conocía anteriormente, y la verdad que hemos alucinado, es de gran ayuda! Muchas gracias.
Pues me lo tomo como un super halago entonces ¡muchas gracias! 😀
Máquina!!
Tú sí que eres grande Héctor, jajaja. Se te echa de menos, crack!
Gracias por tu post Carlos! Me ha parecido muy interesante, aunque quizá me han faltado aplicaciones prácticas reales parecidas al ejemplo que has dado con la ficha de producto y Google Shopping. ¿Alguna utilidad más desde tu experiencia?
Hola Lorena!
Pues mira, por ejemplo el primer caso que pongo: saber si una keyword está siendo geolocalizada. Me ha pasado hace poco de un cliente que salía TOP3 en todas las queries de ‘palabra clave + localidad’ pero nunca en ‘palabra clave’. Al final el tema es que si, por ejemplo, eres un resturante de Sevilla y la gente busca sólo ‘restaurante’ desde fuera de Sevilla, siempre saldrán resultados de la zona. Esto lo puedes comprobar.
También lo estoy usando ahora para ver cuáles de mis resultados están saliendo en uno de estos bloques en concreto. He sacado unos 10 de 180 analizados, pero creo haber encontrado un patrón que tienen unos y no tienen los otros, tengo que hacer alguna prueba. Pero también he podido hacerlo gracias a los footprints.
No sé si estos casos te pueden ayudar. Como digo, soy consciente que es algo que parece bastante trivial, pero creo de verdad que con ingenio puede ser una buena navaja suiza 🙂
Saludos!
Wow, la verdad que un post de los buenos!!! Mira acabo de leerlo y mientras te dejo el comentario para agradecerte que compartas esta información, tengo a la Rana raspando un monton de keywords…
Particularmente para formar las url, utilice el añadir prefijo y sufijo!!!
En particular tengo variaciones en Kw entre movil y pc, y voy a intentar duplicar el ratreo, para ver si realmente me arroja los mismos resultados, muchas gracias por tu post
Muchas gracias por tu comentario, David!
Sí, ten en cuenta que además había algún bloque (en concreto por ahora sólo he visto el de Google Shopping) que variaba de footprint entre desktop y mobile. De todas formas acabé encontrando un trozo del mismo que era común en ambos casos así que debería encontrarlo de todas maneras. En caso que salga en los dos sitios, que como dices no siempre pasa.
Saludos!
Menudo currazo. El post es increíble. Cuando tengas más resultados si escribes otro post, me pasaré sin dudarlo a leerlo. Gracias por tu post.
Muchísimas gracias por tu comentario Adrián, así los currazos son mucho menos currazos. Gracias! 😉
Pufff esto si que es SEO técnico del bueno, y del que se agradece… EL futuro (presente) aplicar estas cositas en nuestra tarea de posicionamiento (y menos enlacitos en periódicos, que también jeje).
Gracias por tu comentario Lolezno! la verdad que a día de hoy sí parece ya más necesario mirar qué muestra Google para una keyword a nivel de módulos, intención de búsqueda… que no quedarnos sólo con volúmenes de búsqueda mensuales. La cosa se está poniendo mucho más compleja e interesante ya 🙂
Muy útil el artículo Carlos. Por artículos como este estoy suscrito a tu newsletter. Junto con el de las extensions de Chrome y otro más, lo tengo en Marcadores.
La parte de Buscar y Reemplazar a mano, ¿has probado con la fórmula de sustituir?
Me alegra un montón que te haya gustado Ricard, gracias por tu palabras. Precisamente hoy a las 17:50 voy a dar una pequeña charla sobre este tema en directo en el SEODay, por si te quieres unir:
https://www.youtube.com/watch?v=NRw3wLSYqPo&feature=emb_title
Saludos!
Hola Carlos,
he visto tu charla del SEODay el otro día y me pareció la mejor, ¡felicidades!
Estaba probando a realizar tu ejercicio y quería hacerte una pequeña consulta:
En Screaming Frog, cuando se configura «Custom Search» con todos los códigos, la regla de concordancia es un «contiene», no el valor exacto. Esto provoca que algunos de los códigos recojan datos que no son correctos. Por ejemplo, el valor «tsuid1», que en tu plantilla tienes para «Definición de diccionario» (para esta también he encontrado el valor «tsuid2x» ^^), englobaría los resultados del valor «tsuid101», que he encontrado en alguna otra búsqueda.
¿Sabes si que hay alguna manera de limitar la medición a los valores exactos?
Muchas gracias,
Hola Ángel, muchísimas gracias por tus palabras. Son un verdadero elogio viendo los compañeras y compañeros con los que compartía evento.
Me he encontrado casos como el que dices alguna vez, y es cierto que puede llegar a pasar. Intento replicar cada módulo sin error unas 10 veces antes de darlo por bueno pero alguno puede patinar aun…
Le iré echando un ojo a ese que dices y alguno más para ver si vemos la manera de dejarlo más fino.
Saludos!
Genial, como siempre, Carlos. Una cosa, sabes cuál sería el Xpath para escrapear con SF el contenido de las preguntas frecuentes en los resultados de Google? No consigo sacarlo. Gracias.
¡Hola, David! Prueba con éste, debería servir:
//div[@class=’r21Kzd’]
Saludos.
Hola, Carlos! Gracias por tu respuesta. Me dice que no es válido este XPath SF, al meterlo en el Custom Extraction. No sé si estoy haciendo algo mal. Lo que quería sacar es el contenido de las 4 «Otras preguntas de los usuarios». Hace tiempo vi un artículo en el blog de SF, pero ya no sirven esos XPath o al menos no me han funcionado. Gracias. Saludos.
Vale, pues mira, más fácil :). Haz esto y listo: https://twitter.com/pixelatumente/status/1422142547992981506
Genial, Carlos. Muchas gracias. Mira que tenía instalada esta extensión desde hace años :-)) …..